Perplexity Sonar Reasoning — Complete 2025 Guide
The Perplexity Sonar Reasoning is a family of web-grounded sequence generation models designed to produce traceable, stepwise reasoning and machine-readable structured outputs. The Pro tier explicitly returns a <think> chain-of-thought block followed immediately by JSON. That pattern is powerful for auditability and programmatic consumption — but it requires robust parsing, validation, and monitoring in production.
Perplexity Sonar Reasoning centric, practitioner-ready long-form guide. It emphasizes conceptual clarity (how Sonar integrates retrieval + reasoning), practical engineering (parsing, schema validation, PoC test harness), performance considerations (benchmarks and latency), cost modeling, and a concrete integration blueprint you can implement today. Perplexity Sonar Reasoning helpful, I provide code snippets you can copy-paste and modify.
Introduction
From an NLP systems perspective, Perplexity Sonar Reasoning is a retrieval-augmented generation (RAG) family where generation is explicitly instrumented with chain-of-thought (CoT) style traces and optional structured outputs. The distinguishing product feature for the Pro model is deterministic output formatting: a human-readable <think> reasoning trace followed by a machine-readable JSON object. That enables two things that matter in production NLP systems:
- Human auditability: You can inspect the intermediate reasoning for quality, bias, or legal scrutiny.
- Programmatic consumption: The appended JSON enables downstream services (indexing, analytics, UI widgets) to consume answers without manual extraction of facts.
For engineers and researchers, the critical implications are around prompt engineering, parser design, schema validation, latency budgets, cost modeling, and QA. This guide translates Perplexity’s product behavior into concrete engineering patterns and testable hypotheses.
Why Sonar Reasoning Matters
- Traceability / Interpretability (audit-ready): The CoT trace provides provenance and a readable chain that helps humans verify claims or trace hallucinations back to reasoning steps. This matters for regulated domains (finance, healthcare, legal).
- Structured programmatic outputs: The <think> → JSON pattern makes it feasible to reliably ingest model outputs into pipelines, analytics, and databases — provided parsing is robust.
- Grounded retrieval: Sonar’s integration with live web search means outputs can cite sources at generation time — crucial for freshness and verifiability in production systems that must surface evidence.
Architecture & core Behaviors
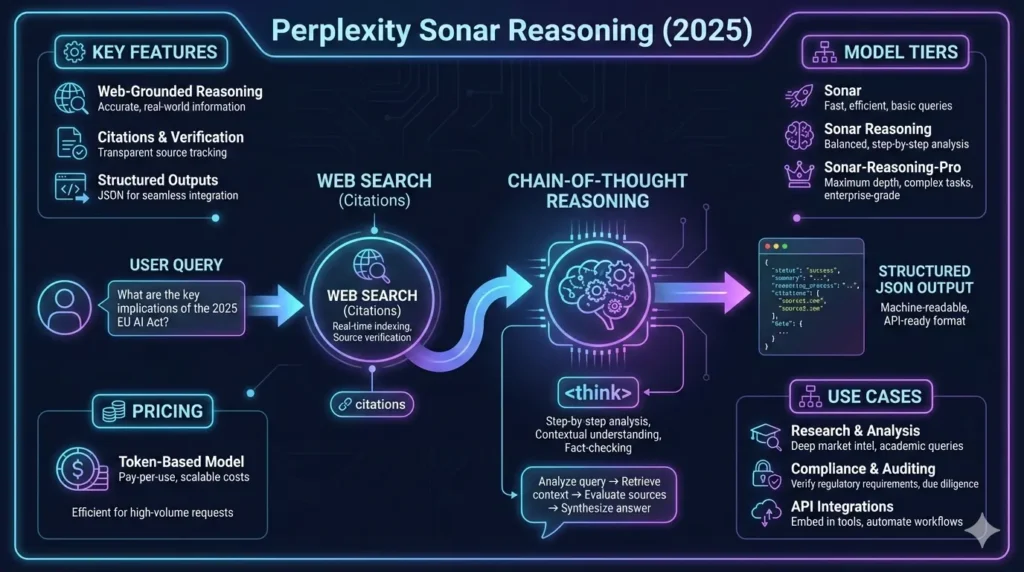
High-Level Pipeline :
- Query ingestion: API receives the instruction and user context.
- Optional retrieval: The model triggers a search or uses an internal retrieval process to incorporate web evidence.
- Reasoning generation: The model emits a stepwise CoT block inside <think> tags.
- Structured emission: Immediately following the <think> block, the model emits a JSON structure containing the final answer, citations, and metadata.
- Post-processing: Application extracts JSON, validates against schema, and persists results + trace for audit.
Implications:
- The model is performing latent reasoning (language-mediated internal state) and revealing parts of it as surface textual tokens (<think>). The visible CoT is not the model’s entire internal state, but it is a useful proxy for interpretability and debugging.
- The retrieval module reduces hallucination risk by grounding statements in web documents, but retrieval quality and result freshness are external variables that affect answer accuracy.
Feature Snapshot & Engineering Notes
| Feature | What it means (NLP view) | Engineering note |
| CoT <think> output | Exposes stepwise reasoning tokens | Useful for human audit & debugging; increases token count & latency |
| Live web search | Retrieval at generation time | Add request fees + variability; snapshot cited pages for audits |
| Structured output (JSON) | Machine-readable payload appended by the model | Requires a tolerant parser + schema validation |
| Multiple tiers | Tradeoffs of cost vs output strictness | Choose tier by SLAs: Responsiveness vs explainability |
| Long context windows | Handle long documents/transcripts | Useful for summarization, but increases cost |
Engineering Tip:
Treat the <think> block as auxiliary evidence, not canonical truth. The JSON object should carry the final, validated result; the <think> block helps explain how it arrived there.
Benchmarks — How to read vendor claims
Vendor leaderboards can be useful, but must be interpreted with an experimental lens.
Key Considerations when Evaluating Benchmark Claims:
- Task match: Does the benchmark reflect your domain or prompts? If not, run a domain-specific PoC.
- Metrics used: Preference votes, BLEU/ROUGE, or human evaluations measure different aspects. Choose metrics aligned to your objectives (e.g., factuality for research assistants).
- Dataset leakage: Ensure the benchmark tasks do not overlap with model training data or widely available web content that advantages one vendor.
Practical Rule:
Vendor claims are a signal to run controlled A/B experiments on your actual workload (measure accuracy, latency, cost, parsing success).
Pricing Explained — Token Math Perplexity Sonar Reasoning
Pricing Models for RAG systems Typically Combine:
- Token costs: Input + output tokens billed per million tokens.
- Search/request fees: Cost per search or per 1k searches.
- Additional overhead: Snapshot storage, caching, and infra.
Representative Example Math :
- Suppose input 200 tokens, output 400 tokens, model pricing is Input $X/1M tokens, Output $Y/1M tokens. Total tokens = 600 tokens = 0.0006 of 1M. Cost = 0.0006 × (X + Y). Add search fee per request.
Cost control strategies:
- Limit max_tokens.
- Use a lower-cost model for simple lookups.
- Cache answers for repeat queries.
- Batch requests when possible.
Semantics and why parsing Matters
The Pro model outputs a textual chain-of-thought inside <think> tags, followed by JSON. From the application perspective, this creates a two-part output:
- Human-facing trace: The <think> block — primarily for debugging and audits.
- Machine-facing payload: The JSON object — the canonical structured answer.
Why is it a parsing problem? Perplexity Sonar Reasoning:
- The raw Generation may contain noise: extra newlines, backticks, stray text prior to or following JSON.
- A naive JSON.parse() on the entire response will generally fail.
- Production systems must tolerate small deviations and either recover or route for human review.
Design Goals For Parsers:
- Be tolerant (find the JSON substring robustly).
- Be safe (don’t execute arbitrary code).
- Validate (use JSON Schema).
- Log and surface failures for human triage.
Validation and Robustness Checklist
- Validate parsed JSON against a schema using jsonschema.
- Add retries: if parse fails, call model with Please output only JSON that matches this schema: ….
- Keep a human-review queue for parse failures and low-confidence outputs.
- Log raw response + parsing errors + user query for debugging and audits.
PoC plan & Test Harness
Goals For the PoC
- Measure factual accuracy on domain-specific queries.
- Measure % parsing_success for Pro outputs.
- Measure latency (p50, p95, p99).
- Measure cost per query, including search fees.
- Evaluate citation relevance and link correctness.
Ten Representative Queries
- Short factual: “When did [company] file for IPO in 2025?”
- Multi-step: “Compare EV subsidies in Germany vs France in 2025 and cite laws.”
- Research synth: “List top 3 academic findings on X (2022–2025).”
- Debugging: “Given failing pytest trace, find root cause and patch.”
- Compliance: “Summarize GDPR cookie banner changes in 2025 with citations.”
- News synthesis: “List 5 causes of supply chain disruption in 2025 with citations.”
- Long context: “Summarize this 12k token transcript and list action items.”
- Code assistance: “Given this code snippet, propose three fixes and include a unit test.”
- Customer support: “Answer this policy question and list citations for each claim.”
- Creative + grounded: “Draft a press blurb about X and list sources used.”
Metrics to capture
- Accuracy (human label: correct / partially correct/incorrect).
- Parsing success rate (valid JSON vs parse failure).
- Latency (p50, p95, p99).
- Tokens per call (input vs output).
- Cost per call (including search fees).
- Citation quality (top 3 checked manually for relevance).
Success criteria
- ≥ 90% parsing success for Pro responses.
- Accuracy ≥ 85% for domain queries.
- p95 latency within your application’s SLA (e.g., <2s for interactive).
Failure Modes, Mitigations, and Monitoring
Perplexity Sonar Reasoning Common Failure Modes
- Parse fragility: JSON extraction fails due to stray text. Mitigation: robust parser + retry + human queue.
- Hallucinated citations: The model invents plausible-sounding but nonexistent sources. Mitigation: validate/fetch top cited links; snapshot evidence.
- Search variability: Retrieval results change over time → inconsistent answers. Mitigation: snapshot sources for audits.
- Cost creep: Unbounded outputs increase token bills. Mitigation: enforce token caps, caching.
- Latency tail: p99 latency spikes due to retrieval or infra. Mitigation: monitor, use caching, fallback models.
Operational Monitoring Checklist
- Track parse error rate (alerts above threshold).
- Track hallucination rate (manual sample).
- Track top failing queries + user-visible incidents.
- Log and rotate raw responses securely (privacy considerations).
- Implement a human review dashboard for low-confidence outputs.
FAQs Perplexity Sonar Reasoning
A: Sonar is a fast, cost-effective search model for grounded answers. Sonar-Reasoning-Pro includes explicit chain-of-thought <think> tokens followed by a valid JSON block for machine consumption, requiring parsing logic.
A: No — Perplexity documents that the <think> reasoning tokens remain; you must extract the JSON payload using a tolerant parser.
A: Use caching, concise prompts, limit max_tokens, choose Sonar (non-reasoning) for quick lookups, batch requests when possible, and run cost simulations with expected traffic.
A: They’re useful indicators, but vendor benchmarks are not a substitute for in-domain evaluation. Replicate tests on your data and measure cost vs accuracy before deciding.
Closing Perplexity Sonar Reasoning
- Sonar_ Use low temperature for deterministic JSON output.
- Enforce max_tokens to bound costs.
- Implement extract_json_after_think with bracket matching and code fence handling.
- Validate output with jsonschema.
- Log raw responses and parse errors; keep a human review queue.
- Snapshot cited pages for audits.
- Run a 10-query PoC and measure parsing success, accuracy, latency, and cost.