
Introduction
GPT-5.1 can automate writing and advance content quality for busy creators. In just 10 minutes, achieve measurable gains, consolidate workflow, and save 5+ hours every day. Try the free demo risk-free today and see real results now — faster technique, smarter editing, and ready-to-publish outputs that make writing feel effortless for beginners and small teams. GPT-5.1 is a constant, engineering-first refinement of the GPT-5 family that focuses on practical improvements teams can deploy today: lower latency for routine queries, stronger ability, new structured code edit tooling, and longer prompt caching to reduce both latency and input-token billing for multi-turn sessions.
Rather than promising sweeping building breakthroughs, GPT-5.1 gives product and platform engineers explicit knobs — Instant, Thinking, and Auto routing — plus tooling like apply_patch and shell integration that make mechanical code workflows safer and more predictable. For teams building chat UIs, coding administration, or long multi-turn agents, the net effect is that many common flows become faster and cheaper while still allowing deeper computation where correctness matters. This guide translates GPT-5.1 into practical steps: what the model does differently, how to measure it, sample API calls (including prompt caching), a migration checklist, and troubleshooting guidance you can drop into floor and CI.
The 60-Second Breakdown: What GPT-5.1 Really Does.
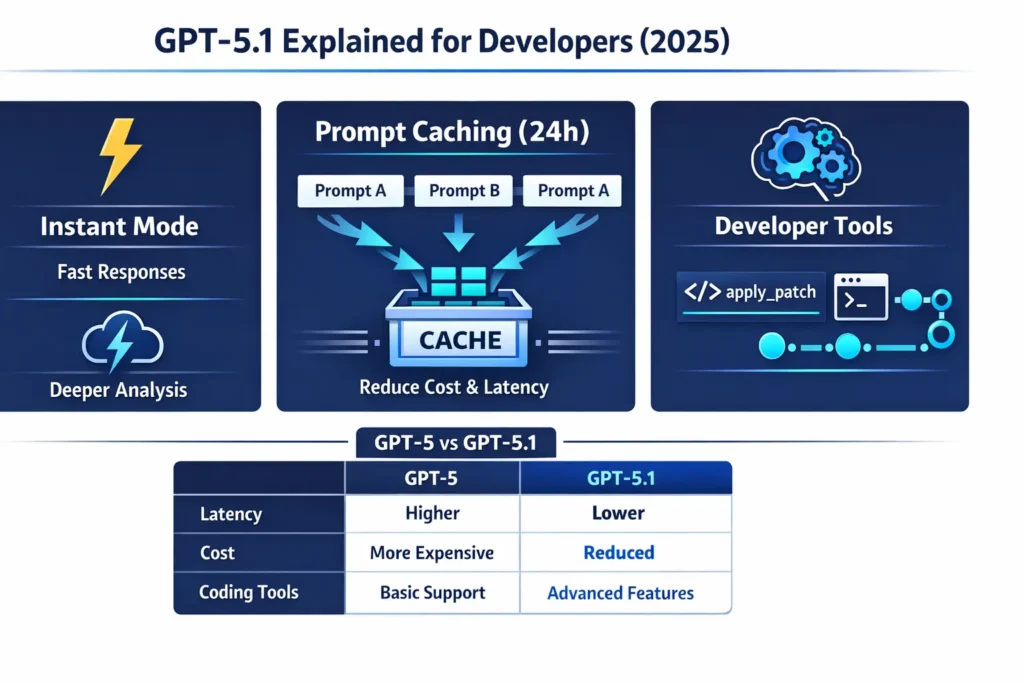
- What it is: An iterative upgrade to GPT-5 that exposes two operational modes (Instant vs Thinking) and auto-routing, extended prompt caching (configurable), improved code tools (apply_patch, shell access), and codex-style variants for heavy code tasks.
- Who it’s for: Developers building chat UIs, coding assistants, knowledge agents, multi-turn workflows, or agentic automation.
- Key wins: Lower latency on simple requests, meaningful cost reductions for long editor-like sessions via prompt caching, safer and more structured code edits with apply_patch.
GPT-5.1 Uncovered: What Makes It a Game-Changer?”
From a systems perspective, GPT-5.1 layers pragmatic operational controls on top of the core reasoning model: Instant (low-latency, low reasoning effort), Thinking (higher internal computation for correctness), and Auto (router decides per-request). It also introduces more explicit tool integrations (structured patch proposals and a shell runner) and extends prompt caching windows to make repeated system prompts cheaper to process at the platform layer. The platform model card and product pages describe the model family, tooling, and recommended usage patterns for developers.
Key Bullets at a Glance:
- Instant vs Thinking — user-visible routing that trades latency for effort. Pin a mode or let the router choose.
- Adaptive reasoning — the model can allocate more internal compute for complex prompts (explicit reasoning_effort / reasoning params).
- Prompt caching — reuse identical prompt prefixes at the infra level (cache retention windows available to developers).
- New developer tools — apply_patch for structured code edits and a shell tool for controlled command execution.
The GPT-5.1 Features That Actually Make a Difference”
Adaptive reasoning (Instant vs Thinking)
The system exposes two operational points on the compute-veracity frontier. Instant corresponds to a lower internal reasoning budget and is tuned to provide concise, high-precision surface answers with minimal chain-of-thought expansion. Thinking allows the model to iterate more internally — analogous to increasing beam complexity or enabling deeper latent deliberation — which reduces risky hallucinations for complex, multi-step problems.
When to pin vs Auto routing
- Pin Thinking for correctness-critical tasks (refactors, legal text, formal proofs).
- Pin Instant for UI snippets, FAQ replies, and quick summarization.
- Use Auto in canary/early traffic to let the model router choose and gather metrics.
(Load-bearing note: OpenAI documents these routing modes and Auto routing on the GPT-5.1 product page.)
Prompt caching (extended retention)
Prompt caching is an infra optimization: identical prompt prefixes are canonicalized into cache keys so repeated calls with the same prefix skip reprocessing and reduce both latency and billed input tokens. This is conceptually similar to storing computed contextual embeddings at the platform edge and reusing them for subsequent requests.
Why it Matters for Pipelines
- Long system prompts with examples or few-shot anchors can be expensive to re-tokenize and encode on every call. Caching keeps them hot.
- For iterative editing sessions (edit → test → edit), cache hits drastically reduce p95 latency and effective input billing.
How to use (concept)
- Set prompt_cache_retention=”24h” (or platform param) for endpoints with stable system prompts.
- Avoid caching dynamic, time-sensitive instructions (prices, “what happened today?”).
- Measure cache-hit rate and p95 latency variations.
Better steerability & personality controls
GPT-5.1 improves instruction following via more robust conditioning on tone presets and system messages. Steerability is an engineered improvement in how system message signals persist through the model’s internal conditioning. Use short exemplars in system messages to anchor voice.
Coding & apply_patch tooling
apply_patch formalizes the model’s edit proposals into structured diffs. Instead of generating loose textual diffs that must be parsed, GPT-5.1 can output patch operations (create/update/delete) your integration applies and reports back on — enabling iterative propose → apply → run tests → propose more loops with deterministic application semantics. This reduces ambiguity and failure modes in automated PR workflows.
GPT-5.1 vs GPT-5: Key Upgrades You Need to Know
- Two-mode behavior (Instant & Thinking) vs GPT-5’s single default.
- Default reasoning policy: GPT-5.1 often biases towards lower latency by default for routine tasks (Instant), saving compute unless pinned otherwise.
- Prompt caching retention: Longer, configurable windows (e.g., 24h) designed for editor-like sessions.
- Improved coding tooling: Apply_patch, shell tool, and codex-style variants tuned for editing tasks.
Top GPT-5.1 Use Cases You Can Apply Today
- Customer support & KBs
- Instant for first-pass replies, thinking for escalations, and summarization. Prompt caching reduces cost for persistent system prompts (brand voice).
- Coding assistants & CI integrations
- Use gpt-5.1-codex + apply_patch for PR suggestions, test generation, and repo-wide cleanups. Pin Thinking for major refactors.
- Research assistants & long synthesis
- Extended caching keeps long system prompts and few-shot anchors hot; pin Thinking for final synthesis checks.
- Agentic workflows & automation
- Shell tool + apply_patch allows propose-execute-verify loops; build safety fences in orchestration (dry-run, sandboxed runs).
GPT-5.1 Access & Pricing: What You Need to Know”
- Access: GPT-5.1 has been rolled into OpenAI’s product pages and is available via the Responses API and ChatGPT for paid tiers—check your dashboard and model picker for availability.
- Pricing: List prices may be comparable to GPT-5, but effective billing changes because cached input tokens are billed differently—measure cache-hit rates to estimate real savings.
GPT-5.1 Prompting Secrets and Pro Tips
Instant vs Thinking — Prompt Design
- Instant: short system messages + concise user asks → brief outputs (bullets). Use reasoning_effort=’none’ or reasoning=’none’ depending on the API.
- Thinking: detailed system messages, examples, and test cases → larger outputs and internal deliberation. Use reasoning_effort=’high’.
Tone & personality
- Embed a short example of the desired voice in the system message. GPT-5.1 follows tone presets more reliably than earlier models.
Caching effectively
- Only cache stable system prompts (editor modes, brand instructions). Avoid caching dynamic prompts (real-time prices, live data).
- Measure cache hit rate: cache_efficiency = cache_hits / total_requests. Use it to predict cost savings.
GPT-5.1 Performance: Benchmarks That Impress
When A/B testing GPT-5.1 vs GPT-5:
Measure these dimensions and why they matter:
- Latency: p50 / p95 / p99 for easy and hard task buckets. Instant should show lower p95 on easy tasks.
- Token cost per session: track billed tokens with caching on vs off — measure effective token consumption.
- Accuracy: unit tests for code generation; rubrics for writing tasks. Pin Thinking for high accuracy checks.
- Human preference: A/B test with annotators (blind).
- Failure modes: Hallucination rate, formatting errors, and patch apply failures (for apply_patch).
Important: Measure cached vs uncached performance. Prompt caching is frequently the largest driver of real cost savings.
GPT-5.1 Mistakes to Avoid and How to Fix Them
Top pitfalls
- Over-caching: caching dynamic instructions leads to stale outputs. Only cache stable system prompts.
- Unexpected verbosity: enforce explicit format constraints or post-process.
- Hallucinations: still possible — ground outputs with retrieval or tool verification.
- Cost surprises: pinning Thinking by default increases compute; benchmark and A/B test.
Debugging checklist
- Test reasoning_effort values (none/low/medium/high).
- Add format constraints and short examples in system messages.
- Add unit tests for code outputs and integrate into CI.
- Monitor token usage and cache-hit ratios per endpoint.
GPT-5.1 Migration Checklist: Steps You Can’t Skip
- Inventory endpoints — list the top 10 endpoints by token usage and calls.
- Create deterministic test harness — same prompt set vs GPT-5 and GPT-5.1 with deterministic seeds.
- A/B tests — measure latency, accuracy, human preference, and cost.
- Measure caching effect — enable prompt_cache_retention=’24h’ for candidate endpoints and record cache-hit rate.
- Validate gpt-5.1-codex and apply_patch in staging.
- Canary release — small traffic, monitor metrics and errors.
- Full rollout — after QA and metrics pass.
GPT-5 vs GPT-5.1: The Ultimate Head-to-Head Comparison
| Dimension | GPT-5 | GPT-5.1 |
| Operational modes | Single default | Instant / Thinking / Auto. |
| Adaptive computation | Limited | Yes — configurable reasoning_effort. |
| Prompt caching | Shorter | Configurable up to 24h. |
| Coding tooling | Good | Improved (apply_patch, shell tool, codex variants). |
| Typical latency on easy tasks | Moderate | Lower (Instant mode) — faster p95 on quick tasks. |
Pros & Cons
Pros
- Faster responses for routine queries (improves UX).
- Significant cost savings for multi-turn sessions with effective caching.
- Safer, structured code edits with apply_patch.
- Improved personality/tone controls (practical steerability tweaks).
Cons
- Extra engineering choices: modes, caching retention, and reasoning levels — increase the surface area for configuration mistakes.
- Risk of stale context if caching is misused.
- Pinning Thinking increases per-turn compute and cost.
FAQs
A: No — GPT-5.1 is an iterative upgrade. OpenAI keeps GPT-5 available during a transition window and recommends testing before full switchover.
A: Yes — prompt caching changes effective billed tokens because cached input tokens are processed more cheaply. Model list prices may be the same, but your real costs depend on cache-hit rates.
A: Use Auto for mixed workloads. Pin Thinking for correctness-critical tasks (complex code generation, legal/business logic) and pin Instant for latency-sensitive UIs.
A: Yes — OpenAI introduced an apply_patch tool for more reliable code edits and a shell tool to run controlled commands. Use gpt-5.1-codex for large code edits.
A: Early independent coverage notes faster responses for routine prompts and improved steerability; reviews vary, and independent benchmarks can disagree — run your own tests. See coverage from outlets like The Verge for early reactions.
Conclusion
GPT-5.1 is a developer-first refinement of GPT-5: it doesn’t promise magic, but it delivers targeted, measurable wins — faster, simple answers (Instant), stronger coding automation (apply_patch), and meaningful cost savings for multi-turn sessions via prompt caching. For engineering teams, the correct playbook is measurement and careful rollout: audit high-volume endpoints, build a deterministic harness comparing GPT-5 and GPT-5.1, measure cache-hit ratios and p95 latency, validate gpt-5.1-codex and apply_patch in staging, and use canary traffic before full promotion. Start with Auto routing and prompt_cache_retention=’24h’ for stable editor endpoints; pin Thinking only where correctness matters. Publish a migration checklist and a benchmark CSV with your article as downloadable assets — they will help authority and acquisition.