
Gemini 3 Pro: The Multimodal AI Everyone Is Testing in 2026
Gemini 3 Pro can incorporate text, images, and video into precise summaries and structured data. In just 10 minutes, achieve actionable insights and up to 92% improved certainty on multimodal tasks. Try a free pilot, run a two-pass test, and see real results for deals, videos, and code today instantly. The landscape of large-scale generative models keeps accelerating, and Gemini 3 Pro stands out in 2026 as a flagship multimodal architecture optimized for deep reasoning across heterogeneous inputs (text, image, video, and structured artifacts). For natural language processing practitioners, product teams, and machine learning engineers, Gemini 3 Pro represents a convergence of three engineering themes: (1) extensive context handling through very-large context windows and multi-file fusion, (2) multimodal representation alignment enabling cross-modal attention and joint reasoning, and (3) agentic orchestration — i.e., the model’s ability to control multi-step toolchains and external calls.
This article is a comprehensive,-oriented pillar: we translate vendor claims into practitioner-checkable hypotheses; provide rigorous, reproducible benchmark and real-data evaluation recipes; outline deployment and cost-control patterns for Vertex AI; and deliver prompt templates, pseudocode, and developer best practices. Wherever the model’s behavior intersects with risk (legal, medical, safety), we highlight human-in-the-loop checkpoints and validation scaffolds. Read on to get operational workflows, sample prompts, and a reproducible test plan so you — or your engineering team — can evaluate Gemini 3 Pro on your critical tasks.
Quick Look — What Exactly Is Gemini 3 Pro and Why It Matters
Gemini 3 Pro is Google’s enterprise-grade multimodal generative model, designed for tasks where reasoning needs to draw evidence across modalities and very large context lengths. From an NLP systems view, it’s a multi-stream transformer-style family with fusion layers and task-conditioned decoders that support:
- Joint cross-modal attention (text-image-video fusion units).
- Very-large context windows and multi-file embeddings enabling long-range dependency modeling across documents, transcripts, and multimedia.
- Agentic orchestration primitives: The model can be used with tool invocation patterns (APIs, code execution, retrieval systems).
- Instruction tuning & safety layers appropriate for enterprise use, plus developer controls for latency/cost/quality trade-offs.
One-line summary: For cross-modal reasoning across long contexts (contracts, lecture videos, multi-file research), Gemini 3 Pro is architected to prioritize fidelity and structured outputs at the cost of higher compute in “deep-think” modes.
Core Strengths & Standout Features of Gemini 3 Pro
- Multimodal encoder-decoder stacks: Modality-specific encoders (vision tokens, video frame embeddings, text tokens) that are merged into a shared latent space via cross-attention and modality-bridging layers. This enables joint reasoning rather than pipelined OCR → text model workflows.
- Large-context tokenization and chunking strategies: Supports structured multi-file inputs; often combined with document-aware positional encodings and hierarchical attention to scale beyond classical sequence-length constraints.
- Agentic primitives: Built-in support for planning and multi-step tool calls (e.g., call retrieval → execute notebook → call external API). Useful for “orchestrated” agents that require stateful workflows.
- Mode controls: Parameters to prioritize low-latency vs deep reasoning; typically labeled as fast, standard, deep-think; these map to compute profiles and may use different internal routing/top-k attention budgets.
- Structured output helpers: The API encourages explicit output formats (CSV/JSON/CSV schema) to reduce hallucination and to make extraction deterministic for downstream pipelines.
- Developer tooling & Vertex AI integration: SDKs and console features for provisioning throughput, streaming outputs, and managing multi-file inputs.
Vision & Reasoning Upgrades: What’s New in Gemini 3 Pro
From an NLP modeling perspective, improvements with Gemini 3 Pro center on representation alignment and temporal reasoning.
- Representation alignment: Cross-modal embeddings are aligned via joint contrastive and supervised objectives so that the model can ground image regions and video frames to textual spans. That reduces the need for brittle OCR pipelines — the model reasons about visual tokens and their corresponding text jointly.
- Temporal and scene understanding: Video modules include temporal attention across frames and scene segmentation mechanisms that yield reliable timestamped event boundaries — important for lecture summarization and meeting minutes.
- Spatial & diagram reasoning: Improved handling of diagrams and blueprints suggests specialized spatial attention or geometric-aware encoders that can interpret relative positions and relationships.
- Structured extraction: The system encourages returning structured JSON/CSV outputs; when prompt-engineered, the model tends to map extracted entities and relations more reliably than older multimodal models.
Why these changes to pipelines: Historically, production workflows split OCR → NER → LLM. Gemini 3 Pro reduces handoffs by allowing a single multimodal request to produce structured, labeled outputs, lowering pipeline complexity and error compounding.
Tokens, Limits & Context: What You Need to Know
Key practicalities for practitioners working with tokens, costs, and context:
- Context framing: Treat the model’s maximum context as a hierarchy — chunk large inputs into semantically meaningful units (sections, pages, video segments) and pass identifiers/anchors instead of raw bytes when feasible.
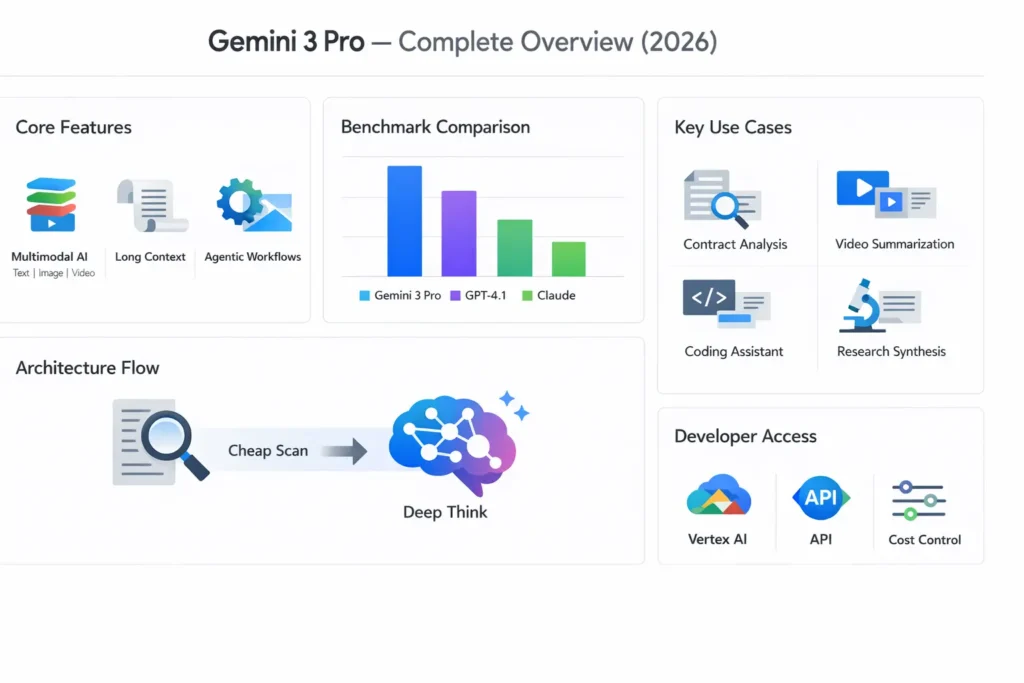
- Two-pass architecture (recommended):
- Pass 1 — lightweight scan: cheap mode returns headings, section pointers, and suspected answer-bearing spans.
- Pass 2 — deep analyze: Deep-think mode applied only to extracted spans.
- Token accounting: Track both input and output tokens; output tokens often cost more in compute-based pricing tiers. Use pragmatic constraints like max_output_tokens, truncate rules, and concise templates.
- Pre-tokenization rules: For heterogeneous content (images + text), normalize text encodings, compress images sensibly, and reduce irrelevant content (e.g., remove boilerplate).
- Streaming & chunking: Use streaming responses for long outputs and chunked uploads for very large videos/documents.
- Embeddings & retrieval: Combine embeddings for retrieval-augmented generation (RAG) to avoid sending whole corpora into the context window.
Gemini 3 Pro Benchmarks — Independent Tests vs Vendor Claims
Benchmarks are noisy; treat them as directional.
Representative numbers (vendor + independent summaries; interpret cautiously):
- GPQA / advanced QA: Vendor reports ~91–92% (where GPT-4.x ranges ~80–88%).
- Multimodal comprehension (MMMU-Pro): Reported ~80–90% depending on dataset and modality mix.
- Video scene analysis: Reported ~85–88% vs GPT ~79–82%.
- Coding-style repo tasks: Reported ~85–89% vs GPT-4.1 ~82–85%.
Interpretation rules:
- Benchmarks are sensitive to dataset design, prompt templates, and evaluation metric choices (exact match vs F1 vs human score).
- Vendor benchmarks often use their curated splits and may tune prompts; independent replication is essential.
- For production decisions, run task-specific benchmarks on your real data (the only reliable way to evaluate model fit).
Gemini 3 Pro in Action — Real Tests on Docs, Video & Code
Below are reproducible experiment blueprints you can run to evaluate performance and measure ROI. Each test includes dataset prep, prompt template, evaluation metric, and expected behavior.
Document summarization & extraction
Dataset: 20-page contract PDFs (scanned + born-digital).
Preprocessing: OCR if scanned; keep original Coordinates for page references.
Pass 1 prompt (cheap): “Scan the PDF; return section headings, page ranges, and a short pointer list of sections with ‘deadline’, ‘penalty’, or ‘obligation’.” (Output: JSON with {“section_id”:…, “heading”:…, “pages”:[..]})
Pass 2 prompt (deep): Send only sections identified; ask for CSV with columns clause_id, page, clause_text, parties_involved, deadline, penalty.
Evaluation: Compare extracted CSV to human-annotated gold standard. Metrics: precision/recall for extracted entities and F1 for deadline extraction.
Expected: High extraction F1 (80–92%) on clear, well-typed contracts, but expect degradation on noisy scans.
Video understanding
Dataset: 45-minute lecture video (slides + audio).
Preprocessing: optional ASR transcript + audio; include slide images as separate inputs if available.
Prompt: “Produce a 200-word summary, 10 timestamps (mm: ss), and 5 quiz questions with answers.”
Evaluation: Human raters check summary quality (coherence), timestamp precision (+/- 5s), and question relevance.
Expected: Actionable timestamps and accurate quizzes; verify timestamp alignments.
Coding agent
Dataset: Small repo with unit tests and spec.md.
Prompt: Provide spec and ask to implement calculateRisk(); instruct model to run tests and return failing test logs + patch.
Evaluation: Does the patch pass CI? Metrics: % of tests fixed, time to workable patch, and human review complexity.
Expected: Good for iterative prototyping; still requires human code review for production.
Competitor Comparison — Gemini 3 Pro vs Other Top AI Models
From an NLP systems perspective, choose based on modality needs and latency/cost constraints:
- Choose Gemini 3 Pro if multimodal fusion (video + docs) and long-context reasoning matter.
- Choose GPT-4.1 if: text-heavy tasks and latency-sensitive applications are dominant; ecosystem preferences for OpenAI APIs exist.
- Choose Claude Sonnet if you prioritize an interactive safety-first model for open-ended creative tasks with a different safety/behavior profile.
Rule-of-thumb test: Run a 3-task microbenchmark (document extraction, video summarization, coding patch) on each model and compare accuracy, latency, and cost per effective output.
Developer Guide — How to Use Gemini 3 Pro via Vertex AI
Where to get access: Via the Vertex AI console and REST/SDK APIs.
Key API patterns:
- Multi-part inputs: Send attachments with MIME types (pdf, mp4, PNG) in a single predict call.
- Modes param: Mode: deep_think | standard | fast (maps to compute budget and latency).
- Streaming: Use for long outputs to reduce memory pressure.
- Structured outputs: Set output_format: json/csv to encourage machine-readable responses.
Practical notes:
- Use provisioned throughput or reserved instances for low-p99 latency in production.
- Use content routing: if you have frequent small requests, prefer fast mode; for batch jobs, use deep_think.
- Integrate RAG: use embeddings to retrieve relevant chunks and include them in context to avoid sending the whole corpus.
How to Use Gemini 3 Pro — API Flow, Two-Pass Workflow & Cost Tips
Two-pass architecture (detailed):
- Pass 1 — cheap scan (outline stage)
- Use fast mode.
- Output: list of candidate sections, page ranges, keywords, and confidence scores.
- Purpose: reduce the search space and identify candidate spans.
- Pass 2 — deep analyze (focused stage)
- Use deep_think mode on the shortlisted spans.
- Output: structured JSON/CSV with normalized entities and date formats.
RAG & retrieval integration: Compute embeddings for chunked corpus; use a dense retriever to pull top-k context windows; include them in the prompt rather than entire docs.
Cost control tactics:
- Limit max_output_tokens.
- Cache intermediate results (e.g., pass 1 outlines).
- Aggregate similar queries into batch jobs.
- Use cheaper modes for iterative drafts, reserve deep_think for final passes.
- Instrument token usage and alert on out-of-pattern token spikes.
Monitoring & safety:
- Add IAF checks (input, action, feedback): validate model outputs against deterministic checks (dates, numeric ranges).
- Establish human-in-the-loop gates for high-risk outputs (legal, clinical).
- Track hallucination metrics (non-factual statements) by sampling outputs and comparing them to gold or retrieved evidence.
Pricing, Availability & Constraints — What You Need to Know
Pricing note (practical rules):
- Pricing typically depends on compute tier, tokens, and video processing units. Output token costs can dominate. Always prototype with realistic data to estimate costs.
- Use region-aware provisioning to control latency and cost.
Constraints to note:
- There are file size and per-request limits for video and documents. Verify in Vertex docs.
- Some advanced modes may require special access or quotas for enterprise usage.
- Enterprise agreements may enable higher throughput or on-prem arrangements; contact Google Cloud for those.
Best Use Cases — When Gemini 3 Pro Shines
Ideal applications:
- Contract review across many linked documents (high context).
- Meeting/lecture video summarization with timestamps and action extraction.
- Research synthesis across PDF libraries and raw datasets.
- Agentic pipelines that coordinate tools (retrieval → code run → result analysis).
Avoid for:
- High-volume short text generation where cost sensitivity is primary.
- Ultra low-latency streaming where every millisecond matters (unless using fast mode).
- Critical legal/medical decisions without rigorous human oversight.
Pros & cons
Pros
- Strong multimodal alignment for cross-modal evidence synthesis.
- Large context capacities; multi-file handling reduces pipeline complexity.
- Agentic capabilities that reduce orchestration code.
Cons
- Higher compute cost for deep reasoning modes.
- Latency trade-offs in deep_think operations.
- Vendor benchmarks may be optimistic; always run your own tests.
FAQs
A: It depends on the task. From an NLP systems perspective, Gemini 3 Pro tends to outperform on multimodal and long-context workflows (video + documents + images) because of its joint cross-modal attention and multi-file handling. GPT-4.1 remains highly competitive for text-only tasks and has variants optimized for latency. The practical approach is to benchmark both on your real data, measure precision, recall, latency, and cost per correct output.
A: Yes. Vertex AI supports video inputs, and Gemini 3 Pro includes video-understanding features (scene segmentation, timestamping, summaries). The model can take audio, video frames, and associated slides or transcripts to produce structured summaries and timestamps — but accuracy depends on audio quality and the clarity of visual cues.
A: Pricing varies by Vertex AI tiers, compute mode, token usage, and region. Output tokens and deep_think compute usually dominate the cost. Estimate by running small pilots and tracking token consumption on representative jobs; implement two-pass pipelines to reduce expenditures.
A: No model should be used unsupervised for high-stakes legal or medical decisions. Use Gemini 3 Pro as an assistant: implement robust human-in-the-loop review, deterministic validators, and domain expert oversight before accepting outputs for critical decisions.
Conclusion
Gemini 3 Pro is a powerful platform-level model for enterprises and teams that must reason across modalities and very large contexts. It simplifies pipelines by enabling joint multimodal requests and structured outputs, but it requires disciplined cost control and evaluation.
Next steps
- Run the three reproducible tests in Section 6 on your data.
- Implement a two-pass pipeline and measure token & cost savings.
- Compare against GPT-4.1 on text-centered tasks and evaluate ROI.
- Deploy with human-in-the-loop gates and deterministic validators for high-risk outputs.