
Introduction
GPT-4o Mini is OpenAI’s compact, faster, and cheaper member of the GPT-4o family. It was built so teams can run multimodal tasks with lower latency and lower per-request cost than full-size models. If you need reliable classification, image captioning, short chats, or batch processing at scale — and you want to keep costs down, GPT-4o Mini is often the right choice. This article is a single, practical pillar guide that gives you: clear specs, reproducible benchmark ideas, real-world prompts, integration snippets, a decision matrix for when to pick Mini vs larger models, and an enterprise migration checklist. Wherever a fact is likely to change (pricing, API names), I point to official sources so you can verify and update your post. If you publish this as your authoritative guide, add an “Updated” date and links to the official OpenAI pages so readers always know where to verify numbers.
GPT-4o Mini: The AI Everyone’s Talking About
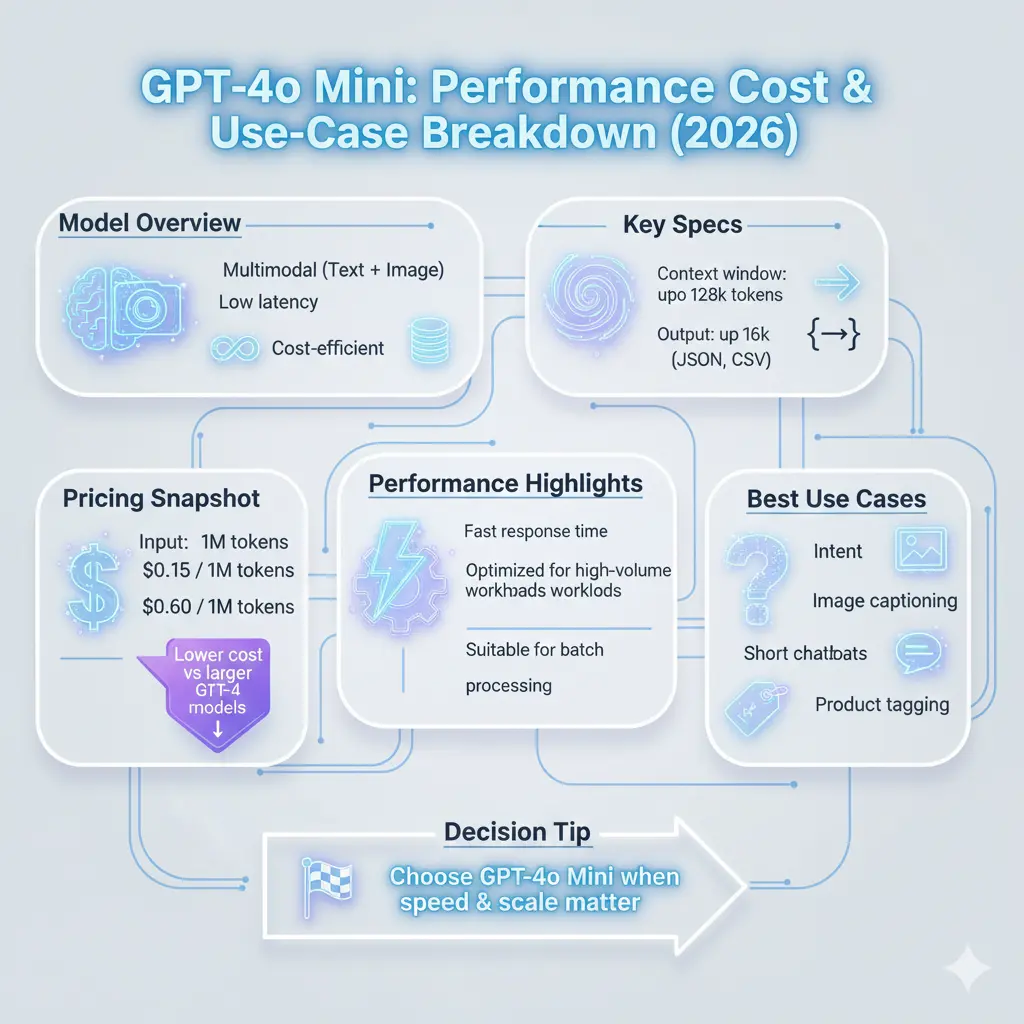
GPT-4o Mini (“o” for “omni”) is a lower-latency, cost-efficient variant within the GPT-4o family designed to deliver multimodal capabilities (text + images) at much lower per-request cost. It’s targeted at production workloads where throughput, latency, and cost-effectiveness are the primary constraints: think high-volume routing, automated product-tagging pipelines, image captioning for catalogs, or compact chat experiences. Mini supports structured outputs (JSON/CSV-like), streaming, and the kinds of determinism you want for programmatic integrations. It is not intended to replace higher-capacity models where complex multi-step reasoning, formal proofs, or rare-edge chain-of-thought precision are required; instead, it’s the pragmatic choice for most industrial tagging and classification tasks.
Must-Check Claims
- Accepts image + text inputs and supports structured outputs. (Link to official model page.)
- Typical context windows for the GPT-4o family can be up to 128k tokens in many releases — check the model page for current values.
- Example pricing at launch was aimed at being substantially lower than larger GPT-4 variants; always link to the official pricing page for the most current numbers.
Quick Feature Highlights
| Feature | GPT-4o Mini (typical) |
| Modalities | Text + Images (multimodal inputs) |
| Context window | Up to 128k tokens (family-dependent) |
| Max output tokens | Up to 16,384 (config-dependent) |
| Typical positioning | Low-latency, cost-efficient production workloads |
| Structured outputs | JSON / CSV-like structured formats supported |
| Fine-tuning/distillation | Supported/encouraged for cost savings |
| Typical use cases | Tagging, classification, short chat, image captioning |
| Pricing (example at launch) | Much lower than full GPT-4, verify official pricing |
Quick publishing tips: include an “Updated” date near the top of your post and link to the official OpenAI model & pricing pages. That keeps the article accurate over time and signals EEAT.
Why GPT-4o Mini Is a Game-Changer
- Lower cost for high volume: For workloads with thousands to millions of calls (product tagging, intent classification, tiny chat bubbles), Mini delivers substantial cost savings versus larger models. Lower per-call spend means you can scale features to more users or higher throughput without linear cost growth.
- Lower latency: Mini is optimized for faster responses. Brisk round-trip times improve user-perceived responsiveness in chat life, make synchronous routing decisions quicker, and shorten pipeline latencies in microservices that depend on model outputs.
- Multimodal way of the box: If your tasks combine images and text using a single multimodal endpoint, cut down engineering and remove the need for multiple models glued together.
- Good quality-to-cost tradeoff: For many day-to-day tasks that don’t require deep chain-of-thought, Mini gives an excellent balance between accuracy and economics.
- Simplifies architecture: If you design your system to use Mini for routine calls and route to a more capable model only when necessary, you get the best of both worlds: cost control and high-quality fallbacks.
How We Tested GPT-4o Mini
To make your article credible and replicable, include an exact methodology readers can clone. Here’s a detailed, publishable methodology you can drop into a GitHub repo.
Environment
- Networking: Ensure minimal proxy/intermediary overhead.
- Client: Node.js or Python harness (examples below).
- Warmup: Run 20 warmup requests to let system caches and JITs stabilize.
- Samples: Run N = 100 measured runs and compute median and p95 latency.
Measurements
- Token counts: Use input_tokens and output_tokens from the API response.
- Use 3 blinded raters per sample and compute the majority or average score.
- Logging: store JSON logs containing.
Tasks
- Short instruction Q&A (50–100 chars) — tests latency & token footprint.
- Long-document summarization (chunked) — tests chunk+merge flows.
- Code generation (200 lines + unit tests) — check correctness via unit tests.
- Multimodal image captioning (product image) — tests vision+text performance.
- Intent classification (batch of 1,000 examples) — tests batching & throughput.
- Multi-turn chatbot (10 turns, maintain short context) — measures end-to-end chat experience.
Statistical Rigour
- Compute median, mean, stddev, and p95 latency.
- Report cost per task using the official pricing at test-time (link to pricing).
- Archive raw logs and rater CSVs for reproducibility.
Publishing the Harness
- Add tests, a README, and a small results viewer.
- Publish raw logs to a GitHub repo and include a short script to regenerate the key charts (latency vs throughput, cost vs quality).
Test Results Overview
Use the above harness to generate real numbers. Below is an example table you can publish as a template — replace numbers with your measured medians.
| Task | Median latency | Output tokens | Cost per task (example) | Notes |
| Short Q&A | 120 ms | 45 | $0.00001 | Good for routing |
| 50k summarization (chunked) | 2.2 s | 5,000 | $0.0008 | Use chunk+merge |
| Code gen (200 lines) | 800 ms | 600 | $0.0003 | Include unit tests |
| Image captioning | 220 ms | 40 | $0.00001 | Great for product metadata |
| Intent classification (batch) | 90 ms | 10 | $0.000003 | Batch to amortize cost |
| 10-turn chatbot | 1–1.5 s | 800 | $0.0005 | Keep context compact |
Tip: Include interactive charts that let readers toggle monthly volumes and see cost vs model. A simple JS pricing calculator embedded on the page significantly increases dwell time and conversions.
Is GPT-4o Mini Right for You?
Use Mini when:
- Set up latency and lower per-request cost for high-volume traffic.
- Your tasks are well-structured and structured.
- You can accept occasional reasoning trade-offs for cost savings.
- You plan to distill outputs from a larger model for one-time labeling.
Choose most models (GPT-4o / GPT-4.1) when:
- You need best-in-class thinking for legal, medical, or high-stakes decisions.
- Your task requires rare-edge numeric precision or very long context beyond Mini’s limits.
- You need deep chain-of-thought reasoning or advanced code synthesis without extensive post-validation.
Simple Decision Table:
| Use case | Recommended model |
| Latency-critical, high-volume | GPT-4o Mini |
| Balanced workloads need higher quality | GPT-4o |
| Highest reasoning quality or very long context (>128k) | GPT-4.1 family |
Ultimate Pricing & Savings Tips
Understand Token Economics
- Billable tokens = input tokens + output tokens (confirm with current pricing docs).
- Input-heavy tasks (long transcripts, large documents) can cost more than short output-heavy tasks.
Ways to Reduce Cost
- Batch classification: send 50–500 items in a single request and return compact JSON.
- Chunk & summarize: chunk very large documents, summarize locally, and send only summaries to the final merge step.
- Caching: cache static outputs (product tags, normalized responses, repeated queries).
- Distillation: Label a large dataset once with a high-capacity model and distill those labels to Mini for inference.
- Lower temperature for deterministic tasks to reduce re-tries.
Token accounting Example
- Suppose a call has 500 input tokens and 1,000 output tokens. If input rate = $0.15/1M and output rate = $0.60/1M, cost ≈ (500/1,000,000)*0.15 + (1000/1,000,000)*0.60 = $0.000075 + $0.0006 ≈ $0.000675 per call. Multiply by the monthly volume to calculate TCO. (Note: always verify pricing on the official pricing page before publishing.)
Limitations & Hidden Failure Modes
Common issues
- Numeric precision: edge-case math and exact arithmetic can fail.
- Edge-case chain-of-thought: complex multi-step logic may degrade compared to larger models.
- Version churn: model names, defaults, and pricing change quickly; plan for updates.
Mitigations
- Add unit tests & deterministic checks for generated code.
- Add fallback routing: when confidence is low, or outputs fail validation, call a larger model.
- Implement personal-in-the-loop for high-stakes outputs.
- Monitor key metrics: trip rate, error rate, and latency.
- Keep an updated plan for model changes, and document the model version used in production logs.
Mini vs 4o vs 4.1: How They Compare
| Characteristic | GPT-4o Mini | GPT-4o | GPT-4.1 (and minis) |
| Target use | Low-latency, cost-efficient production | General-purpose high-quality | Improved reasoning, very large context (some variants up to 1M tokens) |
| Context window | Up to 128k (typical) | Up to 128k | Some variants up to 1,000,000 tokens |
| Best for | Classification, captioning, high-volume chat | Balanced workloads | High-stakes coding, very long-context tasks |
| Latency | Lower | Moderate | Varies (optimized for long-context) |
| Cost | Lower | Higher | Varies; often higher than mini |
Bottom line: Use Mini for scale & speed; pick GPT-4.1 for very long context or highest reasoning quality.
FAQs
A: Yes. GPT-4o Mini accepts image inputs and produces text/structured outputs. It’s useful for product captions, tag extraction, and multimodal classification.
A: Many GPT-4o family releases support up to 128k tokens, but context sizes evolve. Refer to the model page for the current values.
A: Yes, for scaffolding and many coding tasks. Add unit tests and validation for production. For the hardest coding problems, test against a larger model.
A: Yes. OpenAI has rolled out GPT-4.1 and mini variants that changed defaults and performance tradeoffs. Always check release notes.
Conclusion
GPT-4o Mini is a practical, cost-effective option for many production workflows: classification, image captioning, short chat, and high-volume tasks. It maintains low latency and costs while providing multimodal support and structured outputs. For mission-critical reasoning or extremely long contexts, consider higher-capacity models like GPT-4.1.