Introduction
Use Gemini 2.0 Flash. From an engineering and research perspective, Gemini 2.0 Flash is a step toward models that operate across far larger textual and multimodal contexts than previous mainstream families. The central technical capability is the ability to accept and condition on approximately 1 million tokens of context — a magnitude that alters retrieval, summarization, and memory design patterns. Whatever product teams, this means fewer orthogonal systems to stitch together (less external chunking and orchestration), while for NLP researchers, it opens new directions in long-context representation, persistent memory, and multimodal alignment.
This guide reframes the original product- and ops-centered information into terminology and practices an NLP practitioner or engineering team will act on: tokenization and context engineering, memory and retrieval architectures, evaluation strategies (automated + human), prompt templates reframed as structured conditioning patterns, model-variant selection using workload profilers, production deployment on Vertex AI, cost and latency tradeoffs, and a practical migration playbook with observability and safety controls. If possible, the recommendations are framed as reproducible experiments and metrics you can automate during an A/B rollout.
Conceptualizing Gemini 2.0 Flash
From an ML systems view, treat Gemini 2.0 Flash as a set of pretrained and finetuned transformer-based decoders (and multimodal encoder-decoder hybrids depending on variant) that have been optimized for:
- Extremely long-context conditioning — the architecture and runtime allow representing and attending over up to ~1M input tokens. Ante, that implies engineering tradeoffs to minimize the amount and latency (sparse attention, global states, chunking strategies, or particular memory layers).
- Multimodal repair & fusion — text, image, audio, and video are defined by modality-specific token streams that are joined into a shared latent space for joint thinking and generation.
- Low-latency reason — Flash models are mutual and served in configurations set up throughput and low P95 latency for interactive joint.
- Tool-enabled agentic workflows — models are shaped to orchestrate external tool calls (search, calendar, API calls) within chains, and to surface structured actions and verification steps for any state-modifying operation.
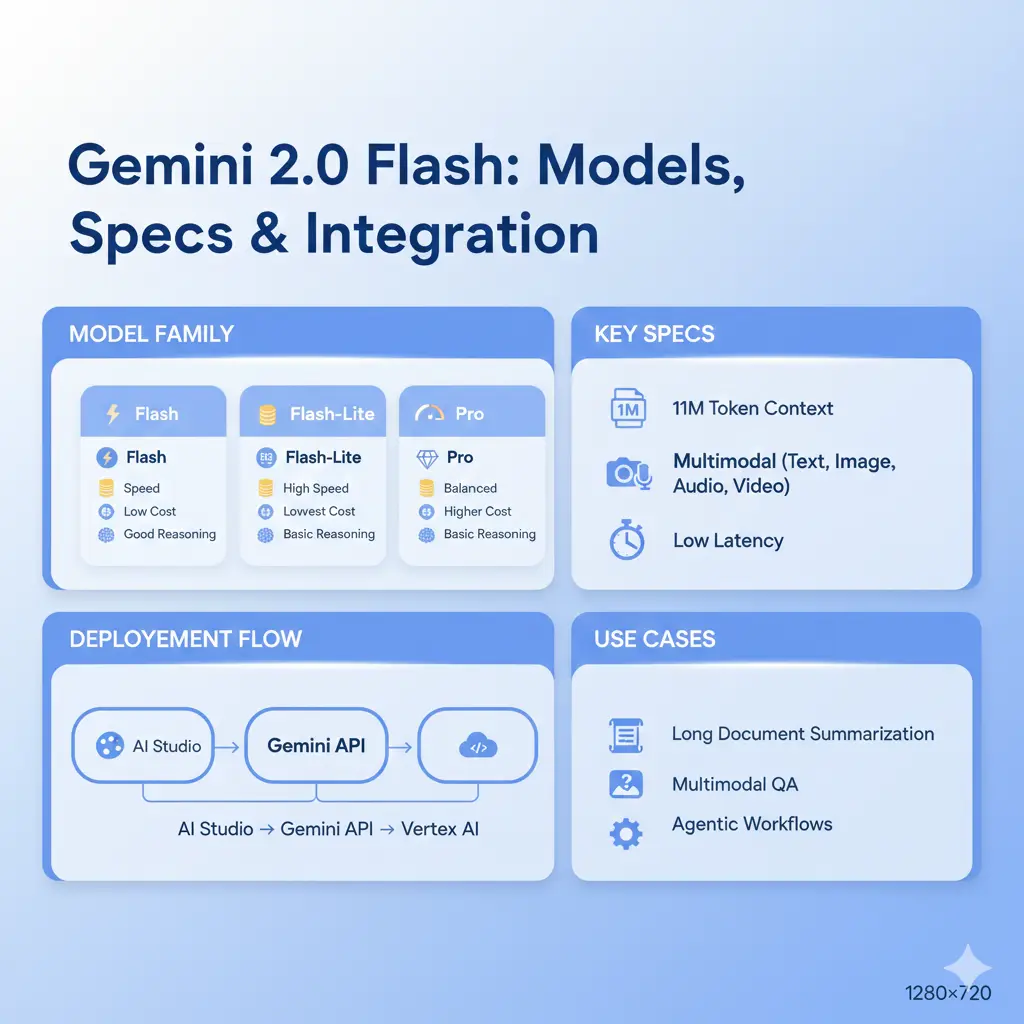
Core Specs & Capabilities
Context window: ~1,048,576 tokens. In NLP terms, that means you can embed entire long documents, logs, code repositories, or multi-session histories as direct conditioning context.
Flexibility: Native support for text, image, audio, and video tokens. Inputs are converted into tone tokens and fused with text tokens.
Waiting & throughput: Engineered for low latency. Use Flash-Lite variants for higher throughput and lower cost when quality demands are relaxed.
Production runtimes: AI Studio and the Gemini API for experimentation; Vertex AI endpoints for production-grade autoscaling and region controls.
Practical NLP note: despite the large window, token and compute budgets still matter. Design to minimize unnecessary token travel; use RAG or summarized contexts where possible.
Flash vs Flash-Lite vs Pro — Decision Matrix
| Dimension | Flash | Flash-Lite | Pro / Thinking |
| Best for | Interactive multimodal assistants, long-document tasks | High-frequency low-cost tasks, quick transforms | Deep reasoning, chain-of-thought heavy tasks |
| Latency | Low (balanced) | Very low (optimized) | Higher (compute-heavy) |
| Cost | Medium | Low | High |
| Context window | ~1M | ~1M | ~1M |
| Strength | Balanced speed + quality | Cost & throughput | Advanced reasoning quality |
| NLP pick | Production assistants; long-context summarization | Bulk short summarization; telemetry parsing | Research, code reasoning, and scientific tasks |
How to pick (practical): Benchmark on your workload. If your application is interactive and requires high-quality multimodal reasoning, choose Flash. If you have massive volumes of short requests (high QPS), choose Flash-Lite. For complex reasoning chains where correctness outweighs cost, evaluate Pro/Thinking.
Benchmarks & Real-World Performance Evaluating the Flash Family
When interpreting Benchmark Claims:
- Relevance matters: Vendor benchmarks are often optimized; run workload-specific microbenchmarks that reflect your typical document lengths and modalities.
- Poem to use: Latency, tokens per second, end-to-end response time (including retrieval and tool calls), cost per 1k requests, hallucination rate (human-eval), and safety-filter triggers.
- Robotic metrics: ROUGE / BLEU for tale and translation, Exact Match / F1 for, and perplexity for open-ended design tasks.
- Human eval: Rating helpfulness, factuality, and correctness on a stratified sample (include long-context cases).
Practical bang: Define latency for both streaming and non-streaming modes. Streaming helps user-perceived latency but may increase implementation complexity for tool-placed flows.
How to Access, Pricing Cues & Deployment
Experimentation: AI Studio and the Gemini API give you rapid iteration for prompt design and small-scale tests.
Production: Vertex AI managed endpoints give autoscaling, region control, and IAM integration. Use model IDs like gemini-2-0-flash-001 or gemini-2-0-flash-lite-001 as appropriate.
Pricing cues :
- Expect pricing to vary by modality (image/audio vs text-only), streaming vs non-streaming, and region.
- Flash-Lite will be the cheapest per call for short tasks.
- Cost optimization is often about balancing model variant choice with retrieval, summarization, and caching strategies.
Gemini 2.0 Flash Integration & Migration
This playbook is an engineer-friendly plan to move a production workload to Gemini Flash while controlling risk.
Preparation
- Collect representative traffic: Sample 1–2 weeks of queries, including long sessions and multimodal requests.
- Define KPIs: Latency P95, cost per 1k requests, hallucination rate, safety hits, and user satisfaction scores.
- Sandbox setup: Create two sandboxes — AI Studio for interactive tuning and a Vertex test endpoint for production-like latency checks.
Local Evaluation & Tuning
- Prompt templates: Build deterministic templates for each flow (summarization, Q&A, image analysis).
- Token accounting: Measure tokens per flow (input + output). Use tokenizers to profile distribution.
- Small corpus tests: Run the same inputs across baseline and Flash to compute automated metrics and sample human ratings.
- A/B experiment
- Traffic split: Route 5–10% of production to Flash variant; log everything.
- Measure & monitor: Latency, cost, correctness, safety flags, and human-eval on outputs.
- Stat tests: Evaluate statistical significance for primary KPIs.
Gemini 2.0 Flash Optimization Before Scale
- RAG: Use retrieval + summarization for old context; keep only recent full chunks.
- Caching: Memoize deterministic outputs (e.g., long document summaries).
- Use Flash-Lite strategically: High-volume short tasks; Flash for richer multimodal queries.
Gemini 2.0 Flash Tool Chaining & Safety
- Idempotency & verification: Require explicit user confirmation for state-changing tool calls.
- Fallback patterns: Define human-in-the-loop fallbacks when tools fail or when confidence is low.
- Rate-limiting Throttle tool calls and capture error classes.
Observability, Alerts & Governance
- Log schema: per-call tokens, model ID, latency, safety-filter reasons, and user rating.
- Dashboards: P95 latency, safety events, cost per 1k, hallucination reports.
- Model pinning: persist model ID/version for reproducibility.
Tokenization, Context Engineering
Tokenization & Modalities
- Use stable tokenizers to compute token counts. For multimodal inputs, translate image/audio into aligned token streams that the model takes.
- Practical tip: Always pre-tokenize and profile sample inputs to estimate cost.
Context Engineering Patterns
- Recency-first windowing: keep recent interactions verbatim, summarize older context.
- Importance sampling: Include top-k retrieved documents based on embedding similarity.
- Chunking: break very large documents into semantic chunks with local summarization.
Retrieval-Augmented Architectures, Memory & Caching
RAG patterns:
- Retriever: Use embedding-based nearest neighbors for candidate documents.
- Summarizer: Compress old documents into high-salience summaries.
- Context router: Decide what to pass verbatim vs summarized using heuristics (e.g., recency, entity mentions).
Memory Architectures
- Episodic memory: Store compressed session summaries per user.
- Indexing: Hierarchical indices (chunk-level, document-level, summary-level) help when the model has a huge context window, but you still want to reduce tokens sent.
- Memory refresh policy: Periodically recompute compressed summaries from raw transcripts to limit drift.
Caching
- Cache deterministic outputs (long-doc summaries, frequently asked Q&A pairs). Store cache keys based on normalized prompts and salient retrieval fingerprints.
Gemini 2.0 Flash Tool-Chaining, Verification & Safety
Tool-chaining considerations
- Keep an explicit execution plan: model outputs an action sequence (e.g., CALL: search(“ACME Q4 results”) -> SUMMARIZE -> DRAFT_EMAIL).
- For state-modifying tools (billing, profile updates), require:
- Explicit confirmation (user must confirm the generated action).
- Signed, idempotent operations on the backend.
- Human review for high-risk operations.
Verification
- Model-generated tool calls should include verification tokens and a record of the context used to decide.
Safety
- Implement filters for PII, medical, and legal content; route to human review when necessary.
- Use the model card guidance and add application-level checks for high-risk categories.
Observability, Metrics & Logging Schema
Key Dashboards
- Cost per 1k queries (broken out by modality).
- Latency percentiles (P50, P95, P99).
- Safety filter hits by category.
- Hallucination rate (human-eval sampling).
- Error rate/tool call failure rate.
Alerting
- Alert on sudden spikes in hallucination rate or safety hits.
- Alert if the cost per 1k increases beyond the threshold after a deployment.
Limitations, Safety & Compliance
- Hallucination: Models can still produce incorrect assertions. Validate critical outputs.
- Tool failure modes: Chained tool calls can fail midway; design rollbacks and idempotency.
- Variant confusion: Always log the exact model ID to avoid confusion across marketing names.
- Regulatory concerns: Data residency, retention, and logging must comply with local regulations; Vertex AI allows region controls to help with this.
- PII & sensitive data: do not store raw personal data without explicit governance and controls.
Pre-Launch Checklist
- Run a 2-week A/B with 5–10% traffic.
- Add per-call token caps and autoscaling safeguards.
- Implement RAG where appropriate; avoid passing whole raw user datasets verbatim.
- Implement tool-call verification and safe fallback behaviors.
- Ensure observability and a human review loop for high-stakes outputs.
- Verify regulatory requirements (data residency, retention).
Benchmarks & How to Run Your Own Tests
Design representative tests
- Create a dataset that includes:
- Short text queries
- Long document summarization requests (10k–200k tokens)
- Multimodal inputs (image+text, audio transcripts)
- Tool-chaining flows (search + summarization + action generation)
Automated Metrics
- Summarization: ROUGE-L, ROUGE-1/2
- Q&A: Exact match, F1
- Generation: BLEU, METEOR (where appropriate)
- Perplexity for language-model modeling tasks
Human Evaluation
- Take a random 1–5% sample of giving outputs for human rating on helpfulness, factuality, and accuracy.
Cost Analysis
- Run the representative workload over a day to compute the cost per 1k queries and compare Flash vs Flash-Lite.
FAQs Gemini 2.0 Flash
A: Flash is the balanced, low-latency model with strong multimodal ability. Flash-Lite is cheaper and faster for simple, repeated tasks. Use Flash for better quality and interactive features; use Flash-Lite for cost-sensitive bulk work.
A: About 1,048,576 tokens — roughly one million tokens. This lets you feed very large documents or long session histories. But still use summarization and retrieval where useful.
A: You can test in AI Studio or the Gemini API, and deploy to giving via Vertex AI (look for model IDs such as gemini-2-0-flash-001).
A: Use Flash-Lite for cheap high-volume tasks, cache identical requests, batch background jobs, set token caps, and run representative cost tests before scaling.
A: Flash is fast and good for many tasks, but for very deep chain-of-thought or research-level reasoning, pick Pro/Thinking variants. They are costlier but often better at complex reasoning.
Conclusion Gemini 2.0 Flash
Gemini 2.0 Flash brings a practical combination of extremely long context, multimodal fusion, and low-latency inference that allows engineering teams to rethink retrieval, memory, and tool-orchestration architectures. It is not a drop-in replacement—teams must carefully design token economics, observability, and safety checks to mitigate hallucination and tool-chaining failure modes. Use Flash-Lite where throughput and cost matter more than the last bit of quality, and reserve Pro/Thinking variants for research-grade reasoning. Start with a measured sandbox and A/B rollout, track human-eval metrics, and iterate.