Introduction
GPT-2 is a canonical autoregressive Transformer used extensively as an educational baseline in natural language processing. First released in 2019, GPT-2 demonstrated how scale (parameters + data) and the pretrain-then-finetune paradigm enable a single causal language model to generalize across many downstream tasks without explicit supervised labels. In terms, it is a causal language model trained with next-token prediction on a large unsupervised corpus. Even in 2026, GPT-2 remains valuable for reproducible research, small-footprint prototypes, pedagogy, and experiments in quantization/distillation. This guide translates practical tips into terminology: tokenization, subword modeling (BPE), autoregressive decoding, pretraining objectives, fine-tuning regimes, inference optimization strategies (quantization, ONNX), safety controls, and prompt engineering — plus code sketches and paste.
What is GPT-2? — Quick Facts & History
GPT-2 is an orthodox transformer-based language model released by OpenAI in 2019. It uses a writer-only architecture and was trained on WebText, a scraped assortment of high-quality web annals. The architecture and training objective are straightforward from a perspective:
- Open-minded: Boost token-level log-likelihood.
- Data: Large-scale freely web crawl (WebText), curated to favor human-shared links; after cleaning, the corpus had on the order of millions of documents and tens of GB of text.
- Release: Staged rollout (small→large) to study misuse risk; final 1.5B checkpoint released publicly.
Why This Matters in:
GPT-2 concretely showed that large unsupervised pretraining establishes strong priors that transfer to many tasks via few-shot, zero-shot, or light fine-tuning. It also catalyzed discussion about release policies and model governance.
Quick Facts Table
| Fact | Value |
| First public announcement | February 2019 |
| Full 1.5B release | November 2019 (staged release) |
| Training corpus | WebText — a filtered web crawl of popular outbound links |
| Model family | Decoder-only Transformer (causal LM) |
| Main public repo | openai/gpt-2 on GitHub |
| Typical tokenization | Byte-Pair Encoding (BPE) subword tokenizer |
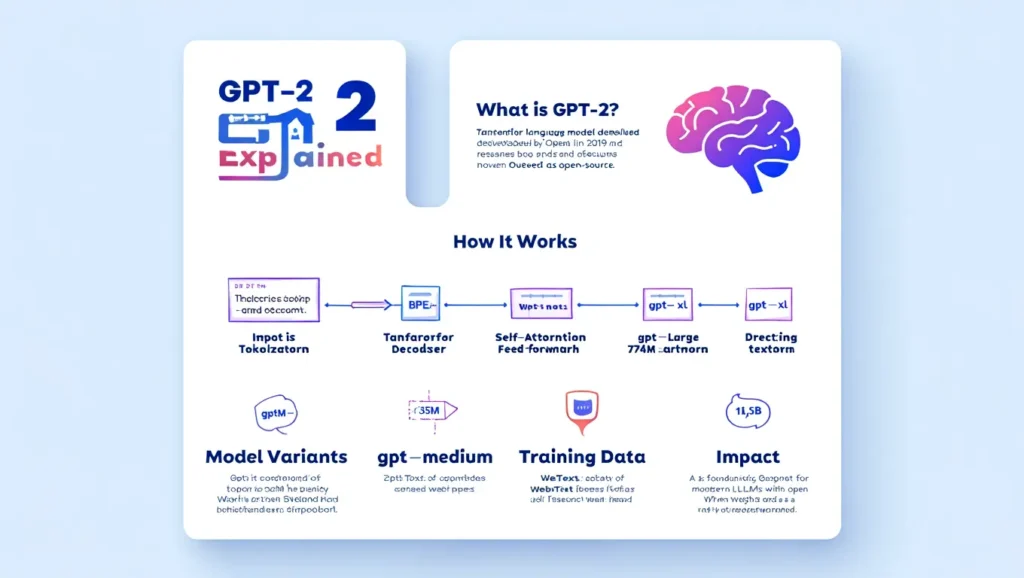
How GPT-2 works
Transformer decoder basics
- Masked multi-head self-attention: Attention over previous token positions (autoregressive masking). Multiple heads allow the model to learn different subspace relationships (syntax, semantics, topical alignment).
- Position embeddings: Added to token embeddings to encode sequence order (static learned positional vectors in.
- Feed-forward network (FFN): Per-position MLP that increases representational capacity.
- Extra connections and layer normalization: Balance training and bring gradient paths.
In inference, the model television logits for the next token based on past tokens and uses a sampling/understanding strategy to produce content.
Improvement and Subword Modeling
BPE slang repair. Subword tokenization balances vocabulary size and unknown-word handling: it splits rare words into frequent subword units, creating a useful glossary.
- Sequence length: Longer inputs map to more tokens due to subword splits.
- Perplexity & efficiency: Tokenization strategy affects model perplexity and speed.
- Decoding consistency: Ensure tokenizer and detokenizer are consistent during deployment.
Pretraining Objective & Optimization
GPT-2 uses standard next-token prediction (minimize cross-entropy). Training optimizes token-level negative log-likelihood with Adam-like optimizers, learning rate schedules, and weight decay. Pretraining is self-supervised: no labeled upstream tasks necessary. During pretraining, the model internalizes statistical regularities (syntax, co-occurrence, semantics) that provide transferable features.
Scale & Inductive Biases
GPT-2’s empirical success emphasized scale: more parameters + more data → better emergent capabilities. However, remains a plain causal LM without instruction tuning or RLHF; its inductive biases come solely from architecture (causal attention) + the pretraining corpus.
Why GPT-2 Mattered — Impact
- Automated disinformation: Mass-generated believable text.
- Spam/abuse: Automated impersonation.
- Attribution & provenance: Difficulty discerning human vs machine content.
GPT-2 Technical Specs
Models and common use-cases:
- Gpt2 (small) — ~124M parameters: great for rapid experimentation and on-device demos.
- Gpt2-medium — ~355M: Better generation quality, still quite efficient.
- Gpt2-large — ~774M: Good for higher-fidelity text.
- Gpt2-xl — ~1.5B: The largest publicly released checkpoint; strong baseline for small-research projects.
Choose size based on tradeoffs: compute budget, latency, and required language quality.
GPT-2 vs modern LLMs — when to pick GPT-2 in 2025
When to pick GPT-2
- Research baselines: Open weights for ablation studies, reproducibility.
- Low-cost inference: Smaller GPUs/CPUs can host small GPT-2 variants.
- Education: Teach tokenization, attention, and transfer learning with accessible checkpoints.
- Edge demos: Offline demos where privacy/offline execution matters.
When to Avoid GPT-2
- Production assistants requiring alignment: GPT-2 lacks instruction tuning/RLHF.
- High-stakes domains: Legal/medical — incorrect or hallucinated outputs are risky.
- Complex multi-hop reasoning: Modern models show better chain-of-thought and reasoning.
Inference optimizations — deploy cheaper and faster
When deploying GPT-2, common NLP engineering optimizations include:
Quantization
Quantization reduces the memory footprint and sometimes increases throughput on CPU/GPU. Modern tools:
- Bitsandbytes for 8-bit optimizers and quantized loading.
- GPTQ/AWQ for post-hoc quantization using second-order approximations.

Guidelines:
- Start with 8-bit for minimal quality loss.
- Validate generation quality (perplexity + human checks) after quantization.
ONNX Export and Runtime
Converting to ONNX and running via ONNX Runtime can be faster on some CPU configurations or optimized inference hardware. Use Hugging Face Optimum for guided exports and benchmarking.
Additional Techniques
- Mixed precision (FP16) reduces GPU memory usage with minimal quality impact.
- Caching past_key_values: Essential for chat applications to reuse prefix computations.
- Distillation: Train a smaller student model to mimic GPT-2 logits for compact deployment.
- Pruning & sparse formats: Remove redundant parameters for inference speed.
Safety, Misuse Risks, and Detection
- Rate limiting: Cap tokens per time per user to limit abuse.
- Safety filters: Toxicity detectors (classifiers), PII redaction, libel checks.
- Origin and metadata: Connect model metadata and, if added, watermarks to crop.
- Animal-in-the-loop: For high-stakes outputs, lacks manual review.
- Erosion and audits: Save logs and review for misuse arrangement.
Remember: Detectors are noisy; combine automated tools with human review and policy rules.
Pros & Cons
Pros
- Fully open weights and code for reproducible research.
- Lightweight options for constrained compute.
- Excellent learning resource for transformer internals.
- Easy to adapt with Hugging Face.
Cons
- Not instruction-tuned by default — poor instruction adherence.
- Weaker safety and alignment compared to instruction-tuned or RLHF models.
- 1.5B still significant resource needs for training/inference.
- Outperformed by modern LLMs in complex reasoning and multi-turn alignment.
Comparison Table — GPT-2 vs Selected Modern Models
| Dimension | GPT-2 (1.5B) | Instruction-tuned Models (GPT-3 family, etc.) | Modern Models (2024–25) |
| Weights public | Yes | Mostly closed/mixed | Mixed |
| Instruction following | Low (untuned) | High (RLHF) | Varies |
| Cost to run | Low–moderate | High | Varies |
| Safety & alignment | Limited | Improved | Varies |
| Best use | Baselines, offline | Production assistants | Production & specialized |
FAQS
A: The full 1.5B GPT-2 checkpoint was free in November 2019, after OpenAI’s release process.
A: GPT-2 was released in multiple sizes; the most publicly set free checkpoint is 1.5 billion parameters.
A: Yes. OpenAI published GPT-2’s code and pradise on GitHub (openai/gpt-2).
A: Fewer variants (124M, 355M) can be fine-tuned on modern laptops with sufficient RAM/CPU; GPUs are approved. For the 1.5B checkpoint, use GPUs with >16GB or cloud selected.
A: Only for low-risk, non-safety-critical duty. For production assistants and safety-sensitive text, prefer modern lesson-tuned models and retrieval-mediated duct.
Downloadable Assets & Diagram Ideas
- Colab Notebook: Runnable inference + fine-tune demo (Hugging Face).
- PDF cheat sheet: One-page commands, hyperparameters, and tips.
- Architecture diagram: Annotated transformer decoder (credit Jay Alammar or your illustrator).
- Quantization benchmark: Before/after memory and latency table.
Advanced Tips
- Quantize then validate: 8-bit quantization often preserves quality; 4-bit demands more validation.
- Distill for edge: Use knowledge distillation to train compact student models from teacher logits.
- Token caching: Reuse past_key_values for multi-turn generation to save compute.
- Adapter/LoRA: For many small fine-tuning tasks, use parameter-efficient methods to avoid storing full checkpoints.
- Ensemble detectors: Combine heuristics, NER-based redaction, and classifiers to reduce false positives for safety.
Conclusion
GPT-2 debris a landmark model that clearly shows how transformer-based language models are determined from large-scale text. While it is no greater state-of-the-art in 2025, its open weights, simple building, and low cost make it ideal for learning, research baselines, and lightweight applications. If you want to understand how modern LLMs cognate, practice fine-tuning, or expand a small, administrable text generator, it is still one of the best starting points.