
Introduction
GPT-5 Pro can cut output costs by up to 70% while improving final-draft accuracy. In just 3 minutes, achieve measurable savings and faster verifications. Read the quick checklist, apply the two-pass fix, and see real results: reduce spend and human edits immediately. Start now to protect your budget, fast today.GPT-5 Pro is OpenAI’s accuracy-first, high-reasoning variant in the GPT-5 family. It’s designed to spend more internal compute per query for deeper multistep reasoning and verification. Use it as the verification/finalization stage in pipelines where being correct matters more than latency or price. This guide converts product-level docs and practitioner best practices into terms: how the model allocates compute, how to measure cost-per-correct-output, reproducible benchmark recipes, prompt patterns that exploit its reasoning style, plus operational controls and competitor context. Where I state product facts (pricing, supported API, feature limits), I cite OpenAI’s official docs.
GPT-5 Pro — The High-Powered AI You Can’t Afford to Ignore
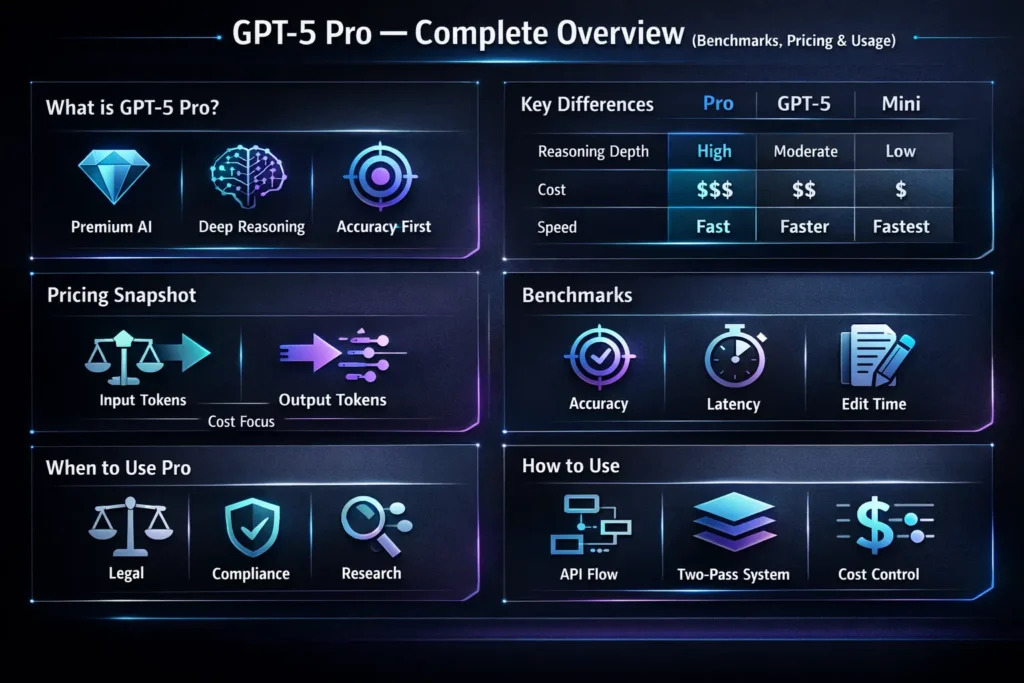
GPT-5 Pro is a high-effort reasoning model in the GPT-5 family engineered to trade throughput for depth. Architecturally and operationally, it is tuned to allocate more compute per token/step during latent inference, resulting in deeper latent planning and more careful token generation. Practically, this shows up as: stronger multi-step decomposition, improved chain-of-thought internal reasoning (exposed in the model’s outputs as more explicit stepwise structure when prompted), and a higher per-call computational cost and latency. -5 Pro is offered via the Responses API only, and it defaults to (and only supports) reasoning.effort: high. Real-world consequences: Some complex requests can take minutes to resolve — design your system for background or asynchronous processing for long-running calls.
Think of GPT-5 Pro as a heavier attention-and-computation budget placed on each decoding step. Where cheaper models prioritize speed and surface fluency, GPT-5 Pro optimizes for internal verification and layered reasoning. If you were to diagram internal inference, Pro’s pass would show more iterative refinement in latent space and larger effective search or deliberation depth per token.
The Vision Behind GPT-5 Pro — Precision Where It Matters Most
- Single-call correctness: Many downstream tasks require that the model’s first/high-confidence output is close to final (legal wording, compliance checks, high-value code refactors). For these, iterative cheap drafts are expensive or risky.
- Internal verification: -5 Pro is intended to internally allocate cycles to validate intermediate claims, cross-check prior context, and produce auditable step lists.
- Multi-turn orchestration: It’s optimized for long multi-turn flows where the model must maintain a stable plan across a long horizon (e.g., multi-document synthesis or complex code transformations).
Key Features — What Sets GPT-5 Pro Apart from Other GPT Models
Core Differentiators
- Reasoning emphasis: Pro enforces reasoning.effort: high; it reserves more compute for inference, which improves complex chain-of-thought behavior.
- Responses API only: Designed for the Responses API to support richer multi-turn interactions and advanced control signals.
- Longer internal processing/background mode: Complex requests may take minutes; background/asynchronous patterns are recommended.
- Feature limits vs other models: Pro may not support all tool integrations (e.g., it does not support Code Interpreter in the current docs). Always confirm in the model docs before assuming feature parity.
- Large context & output windows: Pro supports very large context and output sizes compared with many models (see model page for concrete limits).
Practical implications
- Accuracy-first pipeline placement: Use GPT-5 as the verification/final pass in hybrid flows; avoid putting it on every single draft request.
- Higher cost & latency: Expect higher per-call cost and longer response times. Design for queuing and background tasks.
- Human-in-the-loop synergy: Pro reduces human edit time per output; measure that reduction to justify cost.
- Format-strict outputs: Use JSON/strict templates to reduce token overhead in corrections and re-parsing.
- Diff-based code edits: Send diffs instead of whole files to preserve tokens.
Pricing Demystified — Token Math & Real-World GPT-5 Pro Costs
Pricing evolves. Always check OpenAI’s pricing pages when you publish. The model page and pricing table list per-1M token rates for input and output. GPT-5 Pro example pricing is shown on the model page, and the platform pricing table — input and output are billed separately; output tokens often dominate cost.
Representative published numbers:
- GPT-5 Pro: Input $15 / 1M tokens, Output $120 / 1M tokens (these are Authoritative numbers listed on the official model page; verify on the pricing page before budgeting).
Token math worked examples (use cases)
Example prices are illustrative — always re-run numbers with the live pricing page.
- Scenario A — long generation for a final report: 2,000 tokens total (500 input, 1,500 output)
- Input cost = 500/1,000,000 × $15 = $0.0075
- Output cost = 1,500/1,000,000 × $120 = $0.18
- Total ≈ $0.1875 / call
- Scenario B — short verification pass: 300 tokens total (50 input, 250 output)
- Input = $0.00075
- Output = $0.03
- Total ≈ $0.03075 / call
Takeaway (NLP ops): Outputs dominate spend. Shorter, structured outputs (JSON, bullet lists) and two-pass architectures cut cost.
Cost-control tactics
- Limit max_output_tokens.
- Ask for summaries and paginated outputs.
- Use cached-input pricing when available (send diffs).
- Use cheap models for drafts and only route final outputs to Pro.
- Batch similar requests and employ cache at the prompt level (memoization).
- Monitor tokens and set alarms per endpoint.
Benchmarks & Test Plan — How GPT-5 Pro Performs in the Real World
Why benchmark? Model performance varies by task. Measure correctness, latency, token usage, human edit time, and cost-per-correct-output for your workflows.
What early adopters report: Pro improves reasoning and reduces human edits, but increases latency and cost. Your mileage depends on the task prompt design and the grading rubric. (Do your own evaluations.)
Reproducible Benchmark plan
- Define goals: e.g., correctness (binary/graded), latency, tokens in/out, human edit minutes, and cost.
- Pick representative tasks (5): complex refactor, multi-document synthesis, multi-step planning, SQL generation from messy schema, and legal clause rewrite.
- Establish identical prompts: same system + user prompt across models; for code tests, ensure the same codebase snapshot.
- Run models: GPT-5 Pro, mid-tier and a cheap baseline (mini). Keep the seed and prompt identical.
- Blind grading: Have human graders score outputs without model labels; measure correctness and required edits.
- Compute ROI metrics: $/correct-result and $/minute saved (map saved human minutes to hourly rate).
- Decide placement: If Pro reduces human edits sufficiently to offset per-call cost, adopt it for that workflow.
GPT-5 Pro in Action — Example Performance & Cost Table
| Model | Correctness | Latency | Cost/call | Human edits |
| GPT-5 mini | 75% | 60s | $0.03 | 12 min |
| GPT-5.2 | 85% | 90s | $0.12 | 6 min |
| GPT-5 Pro | 95% | 4–5 min | $0.90 | 2 min |
Interpretation: Convert human edits saved into monetary savings to compute ROI.
GPT-5 Pro Decision Guide — Pick the Right Model for Every Task
Quick rules
- Choose Pro when: Single-call correctness matters, human review is expensive, or mistakes are costly (legal, compliance, final code review).
- Avoid Pro when: High-volume, low-value tasks that require quick turnaround (captions, bulk ideation).
Hybrid best practice
- Draft with cheap models.
- Route verification/finalization to GPT-5.
- Gate high-risk outputs with human review.
Use-case Matrix
| Use case | Volume | Need for correctness | Recommended model |
| Final legal draft | Low | Very high | GPT-5 Pro |
| Bulk blog ideas | High | Low | mini/instant |
| Code review for deployment | Low–Med | High | GPT-5 Pro (final pass) |
| Customer support responses | High | Medium | cheaper GPT-5 variants + Pro for escalations |
| Research synthesis | Low | High | GPT-5 Pro |
How to use GPT-5 Pro — API patterns, prompt recipes, cost controls
Primary interface: Responses API (stateful multi-turn interactions). Use the API’s features (streaming, background mode, and function calling) to manage long-running tasks and complex outputs.
Important: Pro only supports reasoning. Effort: high and may require background/asynchronous handling for long tasks.
Prompt engineering recipes
- Complex decomposition recipe
- System: “You are a precise analyst. List assumptions and number each step.”
- User: “Step 1: Identify inputs and constraints. Step 2: Produce a plan. Step 3: Execute plan. Then give a 3-sentence summary.”
- Why it works: Forces the model to expose an internal plan as explicit numbered steps, which improves verifiability.
- Two-pass verification
- Pass A (cheap model): Draft content.
- Pass B (GPT-5 Pro): “Review the draft. Mark factual mistakes, propose fixes, and rate confidence 0–100 for each major claim.”
- Why: Pro shines at verification, not necessarily at mass generation.
- Cost-aware generation
- Request a tight summary first (e.g., 150 words), then a 5-bullet plan. Set max_output_tokens.
- Structured JSON outputs
- Ask for strictly formatted JSON to reduce token overhead on parsing and re-formatting.
Token-saving tactics
- Send diffs for code.
- Use compressed contexts (summaries) and cache long static contexts elsewhere.
- Request concise bullets rather than long narratives.
Monitoring & safety
- Track tokens per endpoint and set alarms.
- Gate mission-critical outputs with human review and automatic validators (unit tests for code, factual checks for research).
Competitors & Head-to-Head — How Stacks Up
Summary: Other vendors (Anthropic Claude family, others) compete on reasoning and safety. The choice depends on your use case, governance needs, and integration requirements. Always benchmark across providers on your tasks.
Snapshot
| Feature | GPT-5 Pro | Other GPT-5 family | Anthropic Claude |
| Reasoning depth | Very high | High | High (different safety tradeoffs) |
| Latency | High (minutes possible) | Lower | Varies |
| Pricing | Premium | Mid/low | Competitive, varies |
Pros & Cons
Pros
- Deep multi-step reasoning and verification.
- Good for final-stage, high-risk outputs.
- Strong multi-turn behavior in the Responses API.
Cons
- Higher per-call cost and long latency.
- Not all tool integrations are supported (e.g., Code Interpreter).
FAQs
A: GPT-5 Pro is available via the Responses API; access and quotas can vary by account and region. Check your OpenAI account and the Responses API docs for availability and quota limits.
A: Official docs state GPT-5 Pro does not support the Code Interpreter tool. Always confirm the current feature list in the model docs.
A: Not necessarily. Pro is great for reasoning and verification; specialist coding models or other GPT-5 variants may outperform Pro on narrow coding microbenchmarks—benchmark on your codebase.
A: Limit max_output_tokens, paginate results, batch requests, use cached inputs, and route drafts to cheaper models.
A: For long tasks, prefer background/asynchronous patterns to avoid HTTP timeouts; some Pro jobs may take minutes.
A: Pricing changes frequently. Use OpenAI’s pricing page and the model page for current per-1M token numbers before budgeting
A: It supports multi-turn interactions via the Responses API, but tool support varies. Check the model docs for specifics.
A: Run a benchmark on representative workflows, measure human edit time saved, and compute $/correct-result.
A: Yes — intentionally slower to allow additional internal compute per request. Plan for longer latencies.
A: Anthropic’s Claude family and other providers; each vendor has tradeoffs in pricing, tooling, and safety approach.
Conclusion
GPT-5 Pro is an accuracy-first, reasoning-heavy model that pays off when single-call correctness is essential. The recommended adoption pattern is hybrid: cheap models for drafts and GPT-5 Pro for verification and finalization. If you want, I can produce a tailored benchmark plan for three specific workflows (example: code review, legal draft, research synthesis) — prompts, grading rubrics, and a token-cost calculator you can paste into your dev environment.