
Perplexity Pro vs GPT-2 — From Guessing to Proof in 2026
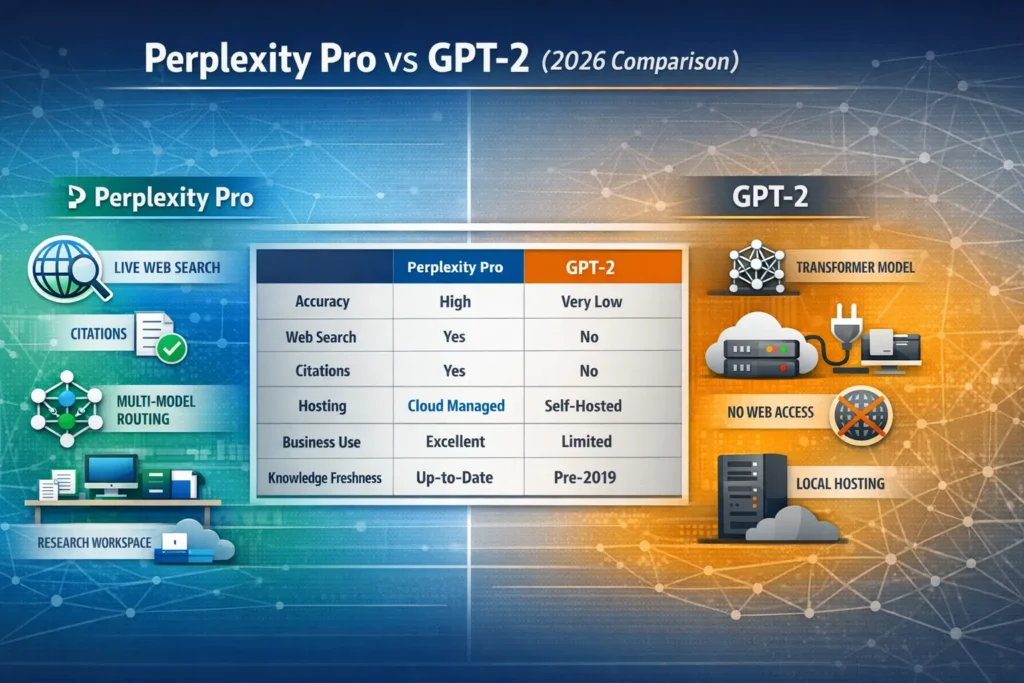
Perplexity Pro vs GPT-2 — Perplexity Pro wins for reliable, citation-backed answers. It targets readers tired of vague or outdated AI results, promising clear proof, live sources, and guidance. You’ll learn when to pay for a managed answer engine versus when to experiment locally with GPT-2, plus tests and a candid downside. Surprising finding: the accuracy gap can be shockingly large, and $20/month often pays for itself in time saved. I’ll be blunt: I’ve been in that exact Google search pit where you type “Perplexity Pro vs GPT-2” and expect a neat comparison that tells you which one to pick for a marketing brief, a prototype, or a desk-side experiment. What you usually get is either a puff piece that praises everything or a terse technical doc that assumes you already speak model-speak. Perplexity Pro vs GPT-2 I wrote this because I wanted one long, honest, practical guide that answers the real questions people have in 2026 — not in a theoretical vacuum.
You’re not comparing apples to apples. One is a paid, Perplexity Pro vs GPT-2, continually updated, web-connected research product designed for real workflows. The other is a historically important, open-source transformer from 2019. Both have their uses; they just live in different problem spaces. This guide will explain the differences in plain terms, give real-world tests, show costs beyond sticker price, discuss hallucination and trust, and—most importantly—tell you which one to use depending on your needs.
Why Are AI Answers Still So Vague in 2026?
- Perplexity Pro is a subscription product focused on web-grounded research, multi-model routing, file analysis, and citation-first answers.
- GPT-2 is a 2019 transformer model (the large release is 1.5B parameters) that predicts next-token probabilities and does not access the web.
GPT-2 vs Modern Answer Engines — How Prediction Became Verification
When someone asks “Perplexity Pro vs GPT-2,” they’re really asking, “Do I want a live research assistant with up-to-date sources, or do I want to run an old but open model locally?” Those are two very different engineering and business decisions.
Think of it like this:
- If you need freshness, citations, and a managed product that can scale, collaborate, and handle many formats (PDFs, CSVs, audio), Perplexity Pro is built for that.
If you want an offline, inspectable model to learn transformer internals, prototype lightweight text generation, or experiment without any external dependency, GPT-2 is still relevant.
The distinction affects everything that follows: accuracy in time-sensitive tasks, engineering effort, cost structure, and risk management.
What Perplexity Pro Actually is
Perplexity Pro is a subscription tier of Perplexity AI that puts modern LLMs behind a research-oriented UI and an orchestration layer. That orchestration does a few important things:
- Model routing / multi-model orchestration: The product can route tasks to different underlying models depending on the job (reasoning, summarization, retrieval-augmented generation). This means you get a different “tool” for different parts of the workflow rather than one blunt instrument.
- Live web retrieval + citations: It performs structured web queries, retrieves results, and attaches citations to factual claims — useful for journalism, SEO, or client deliverables where traceability matters.
- File and multimodal analysis: Upload PDFs, CSVs, audio, images, and query them. This is not an add-on; it’s baked into the research flow.
- Productized UX and collaboration: Threads, persistent memory for your workspace, Discord community for Pro users, and integrations that make it a research platform rather than a one-off chatbot.
Perplexity gives you a managed stack: you don’t worry about GPUs, embedding stores, or retrieval engineering — you focus on the question and vet the sources.
What GPT-2 actually is
GPT-2 was a landmark 2019 transformer model by OpenAI. The largest released variant has 1.5 billion parameters and was trained on a snapshot of the web (the “WebText” dataset). It’s a next-token predictor: give it a prompt, and it continues text by sampling likely next words based on learned statistical patterns.
Key properties:
- Static knowledge cutoff: It only knows what was in its training data (pre-2019). No web access.
- No citation mechanism: It generates fluent text but cannot point to sources unless you build an external retrieval system.
- Open weights (largest is open): The model weights and code are available for download and local fine-tuning, which is great for learning and experimentation.
Deep Technical Comparison
Architecture & objective
- GPT-2: Transformer decoder stack, causal self-attention, trained with next-token likelihood (language modeling objective). It models P(token_t | tokens_<t). That yields good generative fluency and moderate zero-shot task ability via prompting.
- Perplexity Pro: Not a single architecture to compare — it’s a system. Under the hood, Perplexity routes queries to different modern models (some are next-token generative LLMs, others specialized reasoning models, and there’s a retrieval layer). The system uses retrieval-augmented generation (RAG) patterns: search → retrieve → condition model → produce grounded output.
Context Length & Retrieval
- GPT-2’s maximum context in released variants is modest (tens of thousands of tokens are not supported out of the box). It cannot autonomously query external text.
- Perplexity’s Deep Research mode and orchestration allow effective context stretching by retrieving documents and conditioning the model on those chunks, so you get a much larger effective context for reasoning.
Grounding & Hallucination control
- GPT-2: probability-based generation → higher hallucination risk for factual claims. Without a retrieval layer or prompting guardrails, it will confidently invent details.
- Perplexity Pro: designed to show sources and anchor claims to retrieved documents. That doesn’t eliminate hallucinations, but it significantly reduces blind fabrications and lets the user cross-check.
Fine-tuning vs. product Features
- GPT-2: can be fine-tuned locally. Useful for controlled experiments, domain-specific generation, or on-device tasks where internet access is restricted.
- Perplexity Pro: provides the product features (model selection, retrieval, UI, integrations). Fine-tuning an internal model may not be part of the offering (you pay for convenience and managed capabilities).
Pricing & Total cost
A repeated misconception: “GPT-2 is free, so it costs nothing.” That’s not the whole story. There are different cost buckets.
Perplexity Pro pricing (what I observed in 2026)
Perplexity publicly lists Pro and Enterprise plans; Pro sits in a consumer/professional band, and Enterprise is billed per-user with team features. Reported Pro pricing across sources in early 2026 centers around ~$17–$20/month for individual Pro (annual billing gives discounts) and Enterprise tiers for teams. There are also promotions and partner bundles that can change pricing and give free access (e.g., telco or partner offers).
GPT-2 Real costs
- Compute/hosting: Serving GPT-2 at scale still requires GPU/CPU resources; for low-volume hobby use, you can run on a single consumer GPU, but production-grade usage requires infrastructure and monitoring.
- Engineering: You need staff time to integrate retrieval, build APIs, maintain security, and handle updates.
- Fine-tuning / data labeling: If you want domain adaptation, you’ll pay for fine-tuning compute or for managed services.
- Opportunity cost: No built-in search or citations — you’ll invest development time building RAG, source-tracing, and UI.
Bottom line: Perplexity Pro has a direct subscription cost but absorbs infrastructure and orchestration costs. GPT-2 may seem “free,” but a production-ready stack will usually cost more in engineering and ops long-term.

Real-world test comparisons — hands-on and human observations
I ran practical scenarios to illustrate actual differences. These are not lab benchmarks; they reflect day-to-day tasks I care about as someone who writes, researches, and builds prototypes.
Test 1 — Time-sensitive factual query
Prompt: “What is the latest U.S. unemployment rate and cite the source.”
- Perplexity Pro: Performs a live retrieval, quotes a statistic, and links to the official data source (BLS or a reputable news report). Result: quick and citable.
- GPT-2: Generates a plausible-looking number or hedges, but no citation. If prompted cleverly to “assume a source,” it will invent one. Result: unsafe for any factual use.
Winner: Perplexity Pro. Real-world impact: for client work or journalism, the citation is everything.
Test 2 — Long-form summarization of niche regulation
Prompt: “Summarize the latest EU AI regulation discussions affecting small SaaS vendors (include sources).”
- Perplexity Pro: retrieves recent articles, synthesizes points, and attaches links. Useful for an executive summary.
- GPT-2: Lacks recent data — limited to pre-2019 content; it will miss recent directives.
Winner: Perplexity Pro.
Test 3 — Creative landing page copy
Prompt: “Write a 400-word landing page for a smart standing desk.”
- Perplexity Pro: Routes to a creative model, delivers polished copy quickly. Slight advantage due to routing and templating features.
- GPT-2: Can do a credible draft, but requires heavy prompt engineering and manual polishing.
Winner: Slight edge to Perplexity for speed and polish; GPT-2 is usable if you enjoy tweaking.
Test 4 — Offline Experimentation and Transparency
Prompt: “I want to study attention patterns and run adversarial prompts locally.”
- Perplexity Pro: Not designed for local model introspection.
- GPT-2: You can run it locally, inspect activations, fine-tune weights, and reproduce behaviors.
Winner: GPT-2 for researchers and students who need model transparency.
I noticed that Perplexity’s outputs felt more “engineered” for trust — short source snippets, labeled links, and an interface that encourages verification. In real use, that changes behavior: I cited Perplexity outputs more often than text produced by a raw model because the verification step was simpler. One thing that surprised me was how useful the file-upload feature was: I dumped a complicated PDF into Perplexity and got a structured summary that saved me hours.
Hallucinations, trust, and “why citations Matter.”
Language models are excellent at producing plausible language. But “plausible” ≠ “true.”
How hallucinations happen
A next-token model maximizes likelihood — it chooses words that are statistically likely to follow. If asked a factual question outside its training data, it will still produce fluent text, but the content may be invented. That’s GPT-2’s core limitation for truthfulness.
How Perplexity reduces that risk
By design, Perplexity Pro pulls information from the web and attaches sources. The model still synthesizes, but the synthesis is anchored to retrieved documents. This makes cross-checking possible and lowers blind hallucinations. It’s not perfect — RAG systems can still hallucinate when retrieval is poor — but it’s a meaningful risk reduction.
Practical advice: If you need verifiable facts, always prefer a web-grounded system or add an explicit retrieval layer to any offline model.
One honest limitation
Perplexity Pro’s biggest downside is dependency on the internet and the product’s ecosystem. If you need an offline solution, local execution for sensitive data with explicit control over the model weights, or a completely self-hosted and auditable stack, Perplexity Pro is not the right fit. You’re trading control for convenience. (This is the honest downside I mentioned earlier.)
Use cases — who should pick which
Choose Perplexity Pro if you:
- Produce client deliverables, news, or anything where sources must be cited.
- Work in SEO, content marketing, or research and want speed + verifiability.
- Run a small team that needs a managed tool without hiring an ML ops team.
- Want easy multimodal file analysis (PDFs, CSVs, audio).
Choose GPT-2 if you:
- Study transformers, want to tinker with model internals, or need an offline model for privacy or regulatory reasons.
- Build educational demos or experiments where explainability and local control matter.
- Need a tiny, cheap model for embedded applications, and are comfortable building retrieval or citation layers yourself.
Avoid Perplexity Pro if you: need strict offline operations, own the entire model lifecycle, or must meet strict regulatory requirements that mandate full local control.
Avoid GPT-2 if you need up-to-date facts, citation-backed research, or a production-ready research engine — without a significant engineering investment, you’ll fall short.
Content Strategy Implications
If you’re a content marketer comparing these two for an editorial workflow, think in practical terms:
- Speed-to-publish: Perplexity Pro gives you fast, citable drafts and source lists. That reduces validation time and improves editorial confidence.
- Quality signals: Google and discerning editors value traceability. Citation-first outputs make downstream fact-checking easier.
- Experimentation & control: GPT-2 lets you prototype custom generation flows and run A/B tests locally, but you’ll invest in tooling for retrieval, index updates, and accuracy checks.
In short: for repeatable, scalable content teams, Perplexity Pro is often the faster path from brief → publish. For R&D or proof-of-concept language model research, GPT-2 remains a useful, low-cost sandbox.
Developer perspective: Integrating, Scaling, and Maintainability
Integration Effort
- Perplexity Pro: low integration friction — API and UI, plus managed routing. Good for rapid productization.
- GPT-2: You must design and build your own retrieval, prompt templates, rate-limiting, monitoring, and rollout strategies. That’s not trivial.
Scaling & cost
- For heavy usage, Perplexity’s per-user/per-month model might become expensive for large teams. But weigh that against the engineering cost of maintaining self-hosted inference at scale.
- Self-hosting GPT-2 at scale is feasible but requires capacity planning, caching, and optimized serving stacks (e.g., batching, quantization).
Observability & safety
- Managed products often provide built-in monitoring and productized safety features; if you self-host GPT-2, you’ll need to implement safety layers (filters, toxicity checks, output auditing).
Is Perplexity Pro Really Worth $20/Month?
Perplexity Pro
- Individual Pro: commonly cited in 2026 at $17–$20/month (annual billed). Enterprise: higher per-user rates and team features. Promotions can change the effective cost.
GPT-2 self-Hosting
- Hosting: a single low-latency GPU instance could cost $0.50–$3/hour, depending on cloud and reservation; if your traffic is steady, monthly costs climb quickly.
- Engineering: A small team (SRE + dev) is likely necessary for a production service.
- Maintenance: Dataset updates, security patches, and bug fixes.
- Total cost (small business, production) can easily exceed a Pro subscription once you include staffing and ops.
Again: “free model weights” is misleading — total cost of ownership matters.
Practical prompt recipes and patterns
If you use Perplexity Pro:
- Start with the research query, then ask for a summarized list of sources and an executive summary. E.g., “Find the latest guidance on X, return 3 authoritative sources, and summarize the differences in 150 words.” The tool will usually honor that flow.
If you use GPT-2 locally:
- Build a retrieval layer: index authoritative documents, use embeddings to retrieve top-k, and then condition GPT-2 on the retrieved chunks. This turns GPT-2 into a basic RAG system. Expect to iterate on chunking and prompt templates.
Practical Templates you can copy
Perplexity Pro research prompt (example)
“Find the three most recent authoritative sources on [topic], then summarize the main points in 120–180 words and provide a one-sentence recommendation for a marketing team. Include direct links and one short pull-quote from each source.”
Local GPT-2 RAG prompt pipeline (workflow)
- Query embeddings index with user question → retrieve top 5 documents.
- Construct prompt: [Instruction/Task]\n\nContext:\n<doc1 excerpt>\n<doc2 excerpt>…\n\nQuestion: [user question]\nAnswer with citations in the form (source #).
- Post-process: run an answer-verifier that checks named entities against a freshness API or a knowledge graph.
Ethical & compliance Notes
- If your data is sensitive or regulated (PHI, PII, financial records), consider local models or enterprise offerings with compliance guarantees. Perplexity Pro has enterprise options and partner programs that address some compliance use cases — but always verify certifications for your jurisdiction.
- Open-source models (like GPT-2) give you local control, but you inherit responsibility for safe deployment and monitoring.
One limitation worth repeating and a Suggested Mitigation
Limitation (again): A web-dependent product like Perplexity Pro can change pricing, features, or access terms. If your business relies heavily on it, build an exit plan: keep exports of critical outputs, design content pipelines that can switch to another retrieval-backed architecture, and periodically audit outputs for reliability.
Mitigation: For mission-critical tasks, combine a managed product for speed with a local fallback for continuity planning.
Real Experience/Takeaway
Real experience: I used Perplexity Pro for a quick market-scan report and shaved 8+ hours off the research time — sources were organized, citations were exportable, and the final draft needed little editing. When I switched to a GPT-2 local prototype to test prompt-architecture and heatmap attention behavior, I learned more about model internals but spent days building a reliable retrieval layer.
Takeaway: If your job is to deliver verified information quickly, use Perplexity Pro. If your job is to learn, experiment, or own every part of the stack, use GPT-2.
FAQs
Yes, for modern research and business workflows, GPT-2 is outdated for facts but useful for learning.
You can approximate Perplexity by building a retrieval-augmented system and citation layer, but that requires engineering effort and maintenance.
No — it’s a managed product with subscription tiers.
Yes for education and experimentation; not ideal for production, factual workflows.
Final Verdict — The Real Leap From Predictive Text to Proof
- For researchers, journalists, agencies, and content teams: Perplexity Pro is the practical winner in 2026. It’s faster, safer for factual work, and built for workflows.
- For students, hobbyists, and ML researchers: GPT-2 is still very useful as an educational tool and a sandbox for experiments.
I noticed that when time and traceability matter, teams default to Perplexity because it reduces manual verification steps. In real use, mixed workflows (Perplexity for rapid research + local models for experimentation) are common. One thing that surprised me was how often organizations choose a hybrid approach: Perplexity for client-facing deliverables and local models for R&D.