Introduction
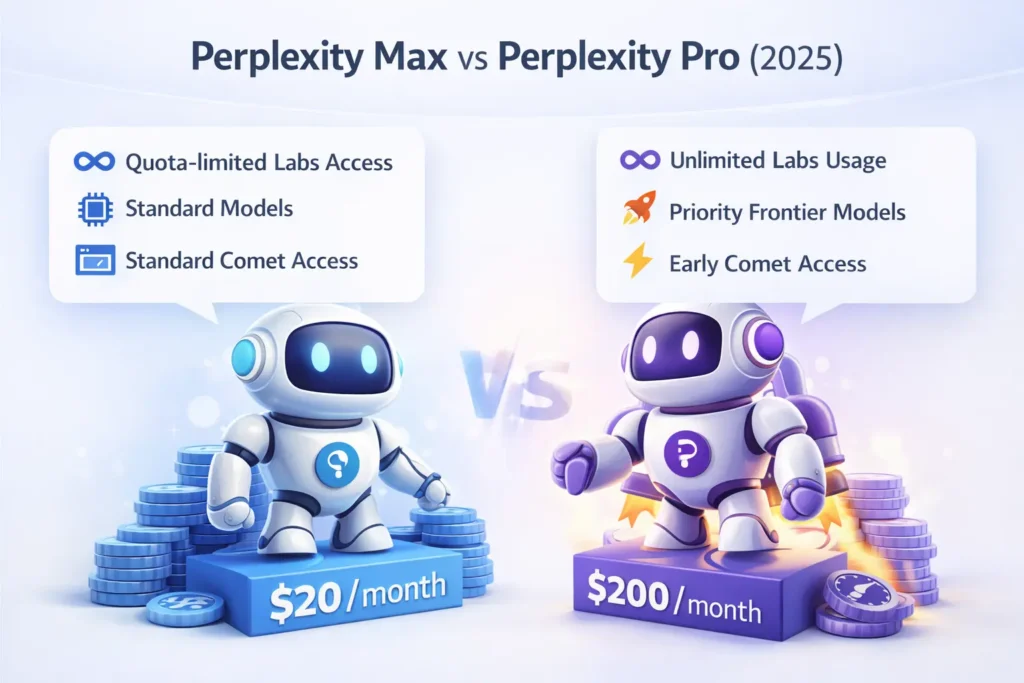
In 2025, Perplexity Max vs Pro sent a clear two-tier consumer/product strategy: Perplexity Pro (the normal individual tier) and Perplexity Max (the premium, high-throughput row). : If you think like a practitioner, choosing between tiers is a question of inference budget, experiment parallelism, access to frontier checkpoints, and toolchain stability. Perplexity Pro is the everyday choice for researchers and creators needing reliable retrieval-augmented generation (RAG), fast model inference, and useful summarization. Perplexity Max vs Pro is targeted at teams and power buyers who need fast Labs throughput, priority access to bleeding-edge model versions, and lower curbing delays for model runs. The official product pages list Pro at $20/month and Max at $200/month.
Max or Pro — What’s Right For You?
- Perplexity Pro ($20/mo): Best for individual practitioners who run moderate RAG jobs, occasional long-form generation, and standard model inference with sensible quotas. Good trade-off between cost and capability.
- Perplexity Max ($200/mo): Best for heavy throughput use cases: many parallel Labs jobs, frequent heavy RAG/embedding use, continuous batch report generation, and teams that must avoid throttles and queuing. Max gives priority access to new model releases and early products like Comet.
Price & Billing at a Glance
Perplexity also documents enterprise and seat-based offerings for organizations. Check Perplexity’s enterprise pages for admin/SLAs and seat-based rates.
Feature-by-Feature
- Monthly price: Pro = $20; Max = $200.
- Labs access (inference quota vs unlimited): Pro = generous but quota-limited; Max = effectively unlimited Labs jobs and higher throughput priority.
- Frontier model priority: Pro = access to advanced models but possibly delayed; Max = priority routing to newest frontier checkpoints (early access to o3-pro, Claude Opus lines reported).
- Comet browser & product bets: Historically, Max got early Comet invites; Comet has since expanded to broader availability, but Max historically gave earlier access during rollouts.
- Support & SLAs: Pro = standard; Max = priority support and faster escalations.
Interpreting Product Claims in Strict
Product marketing talks in months and features; Engineers think in Tokens, requests/sec, queue length, and model switches. Here’s how the marketing lines map to actionable engineering concepts:
- “Unlimited Labs” → Infinite practical inference budget
- NLP translation: no enforced rate-limiting thresholds for Labs jobs, which removes the need to implement client-side batching or backoff strategies. This reduces queuing delays and administrative orchestration for large parallel experiments. Evidence: Perplexity’s Max announcement and help pages describe unlimited Labs and higher throughput.
- “Priority access to frontier models” → Lower model rollout latency & preferential routing
- NLP translation: Max users receive earlier access to updated model checkpoints (new versions of reasoning models, experimental weights). That implies shorter wall-clock time between a public model release and the ability to run experiments on that model for A/B or evaluation. Reporting indicates access to OpenAI’s o3-pro or Anthropic variants by default for some Max jobs.
- “Comet early access” → Integrated agent/browser tooling
- NLP translation: Comet materially changes the RAG pipeline: browser-integrated page context becomes a first-class retrieval source, enabling live web context retrieval and summarization at inference time. Early access gives teams time to integrate Comet-enabled flows before general availability. Perplexity initially rolled Comet to Max and then expanded globally.
- “Priority support & enterprise readiness” → Faster incident MTTR and production confidence
- NLP translation: Priority support reduces mean time to resolution (MTTR) for outages or model regressions — crucial if your app’s production inference depends on Perplexity as a core service.
Deep dive — What Actually Differs
Labs access and throughput
Pro: Generous quota, good for intermittent experiments.
Max: Unlimited Labs jobs; removes quota-based throttling.
implications:
- If you run frequent parallel evaluation jobs (for example, batch BLEU/ROUGE/EM/perplexity evaluations across many checkpoints), quotas force you to throttle or queue. Unlimited Labs means you can spin many parallel jobs without client-side orchestration, reducing scheduler complexity.
- Performance matters more than raw model capability when you’re doing hyperparameter sweeps; queueing and throttling can be the dominant cost of experimentation. Max directly reduces orchestration friction.
Frontier Model Access and Model Selection Strategies
Pro: Access to advanced models, but potentially with delayed access to bleeding-edge releases.
Max: Priority access — ideal for teams doing model comparison experiments (A/B testing new checkpoint vs baseline).
Implications:
- Early access to new checkpoints (o3-pro, Claude Opus 4 — as reported) enables immediate evaluation for hallucination rate, factuality, instruction following, and few-shot generalization. If your product is model-sensitive, being first to evaluate can be an advantage.
Product tools like Comet (agentic tooling & integrated retrieval)
Comet transforms a RAG architecture by making the live web context a seamless retrieval source. Initially launched to Max, then widened to Pro and public users as Perplexity scaled Comet. If your pipeline depends on an integrated browsing agent to fetch personal or ephemeral context (emails, calendar, private pages), Comet’s integration can drastically reduce engineering work to stitch external retrieval endpoints.
Support, SLAs, and production Dependencies
Max includes priority support — important when Perplexity behavior impacts client deliverables. For applications that provide client-facing summaries or automated reporting, priority support shortens incident windows and helps when model regressions change output characteristics.
Security, Privacy, and Risk Perplexity Max
No product is flawless. When you increase automation and rely on agentic tools (like Comet), you also accept new attack surfaces: prompt injection, credential exfiltration via browser plugins, or malicious page manipulations that manipulate summarization context. Independent auditing and security reporting flagged potential attack surfaces in Comet during its early rollout — a reminder to treat new agentic browser features as sensitive integration points and to implement strict input sanitation and human-in-the-loop checks when using Comet in production.
Perplexity Max vs Pro: Who Should Choose Which Plan — Technical Scenarios
Choose Pro if:
- You are a solo researcher running occasional RAG pipelines and fine-tuning experiments.
- You run a few daily Labs jobs and don’t hit quotas.
- You want a low-cost option while retaining model access for most research tasks.
Choose Max if:
- You are a team that executes daily batch inference pipelines for production reports.
- You perform frequent A/B model comparisons and need early access to new checkpoints.
- The time cost of queueing, re-running, and managing throttles is greater than the incremental subscription cost.
Perplexity Max vs Pro ROI and Cost-Per-Use Models
ROI template (NLP edition):
hours_saved_per_week × hourly_rate × 4 (weeks) > price_change
Solo Creator (Pro)
- Time freed by higher quota / faster runs: 2 hrs/week
- Hourly rate: $30/hr
- Monthly amount: 2 × 30 × 4 = $240
- Pro cost: $20/month
- Verdict: Pro easily justified.
Two-Person Agency (Max candidate)
- Time lean due to quotas: ~1 hr/day per company (or 2 hrs/day total).
- regular hourly rate: $60/hr
- Monthly saved: 1 × 60 × 22 workdays ≈ $1,320 (per person/week, math can be cooked)
- Incremental cost (Max vs Pro): ≈ $180/month
- Verdict: Max can pay for itself once you factor in improved throughput and avoided orchestration work.
Product R&D (Model Evaluation)
- Frequent A/B testing, hyperparameter sweeps, and ensemble evaluations. The speed gains in wall-clock time and lower orchestration effort often dwarf subscription cost.
Practical Lab Checklist
- Measure Labs job count per month — how many batch runs and how many concurrent jobs do you start?
- Track job queue times — what is your average queue latency? Multiply saved latency by team headcount and hourly rates.
- Record failed runs due to quotas — outages and retries cost developer time.
- Count model rollouts you want early access to — are you depending on a specific new model release?
Side-by-Side Technical Tables
Model & AI Capabilities
| Capability | Pro | Max |
| Advanced AI model access | Yes (general) | Priority / earliest access to frontier models. |
| Default runtime models for Research mode | Advanced models (subject to availability) | Advanced models prioritized and routed earlier. |
| Unlimited deep research | No (quoted) | Yes (effectively unlimited). |

Labs & usage limits
| Category | Pro | Max |
| Labs usage | Quota-limited | Unlimited / priority throughput. |
| Batch workflows | Needs orchestration | Full support (no throttle). |
Support & product access
| Feature | Pro | Max |
| Priority support | No | Yes (faster escalations). |
| Early Comet access | Limited | Historically, earlier invites to Max. Comet later expanded broadly. |
Perplexity Max vs Pro Common Objections & Evidence-Based Answer
Objection: “$200/mo is too expensive.”
Answer (NLP): Compare it to developer hours lost to queueing and orchestration. If you can model how often quotas block experiments and multiply by hourly rates, you get a fair cost comparison. See ROI scenarios above.
Objection: “Why not just buy multiple Pro seats?”
Answer (NLP): Multiple Pro seats multiply seat capacity but often keep per-seat quotas. Max removes global throttles and provides priority routing for model and feature rollouts that multiple Pro seats may not replicate.
Objection: “Is my data used for training?”
Answer (NLP): Refer to Perplexity’s Trust Center and privacy docs for the latest policy. Always review the product’s data-handling policies for training, retention, and redaction specifics.
A pragmatic Migration Strategy
- Baseline instrumentation: Track Labs job counts, queue times, failed runs, and time spent on orchestration. Apply golden metrics for MTTR and job latencies.
- Pilot with real workloads: Run a month-long Max pilot with production-like loads (A/B testing, report generation) and record delta in wall-clock time, retries, and developer hours saved.
- Evaluate model regressions: Use the pilot to estimate the impact of early model changes on output behavior (hallucination rates, factuality). Early access is only valuable if the model changes produce meaningful product improvements.
- Security review: If you plan to integrate Comet or agentic features, perform threat modeling and prompt-injection audits. Independent audits have flagged Concerns in early Comet rollouts — treat these tools with caution until mitigations are proven.
Risk checklist
- Model drift monitoring — track distributional shift after each upstream model update.
- Prompt injection defenses — sanitize web retrieval context and implement allowlists for agentic actions.
- Data retention & privacy — confirm whether Perplexity uses user data for training and whether you need DPA or SOC2 evidence.
FAQs Perplexity Max vs Pro
A: Pro is $20/month; Max is $200/month with much higher usage limits and priority access.
A: Users or teams who need unlimited Labs queries, the earliest model access, and priority feature access.
A: Yes — including seat-based Enterprise Pro and Enterprise Max with admin controls and compliance features.
A: Yes — many teams trial a single Max seat for a month to measure benefits.
A: Public case studies remain limited; internal metrics and time saved are often the best proof.
Conclusion Perplexity Max vs Pro
- Perplexity Pro ($20/mo) is the pragmatic choice for most individual researchers and creators who run moderate Lab jobs and want cost-effective access to advanced models and Comet features as they roll out broadly.
- Perplexity Max ($200/mo) is for teams that suffer from throttles and queueing, run many parallel batch experiments, or require the earliest access to frontier models and product betas (historically including Comet). The Max tier simplifies orchestration by eliminating quota-driven bottlenecks.
Measure, pilot, and instrument — do the math using the ROI template above, run a real pilot with your workload, and evaluate time-to-insight and developer hours saved before you upgrade.