
Introduction
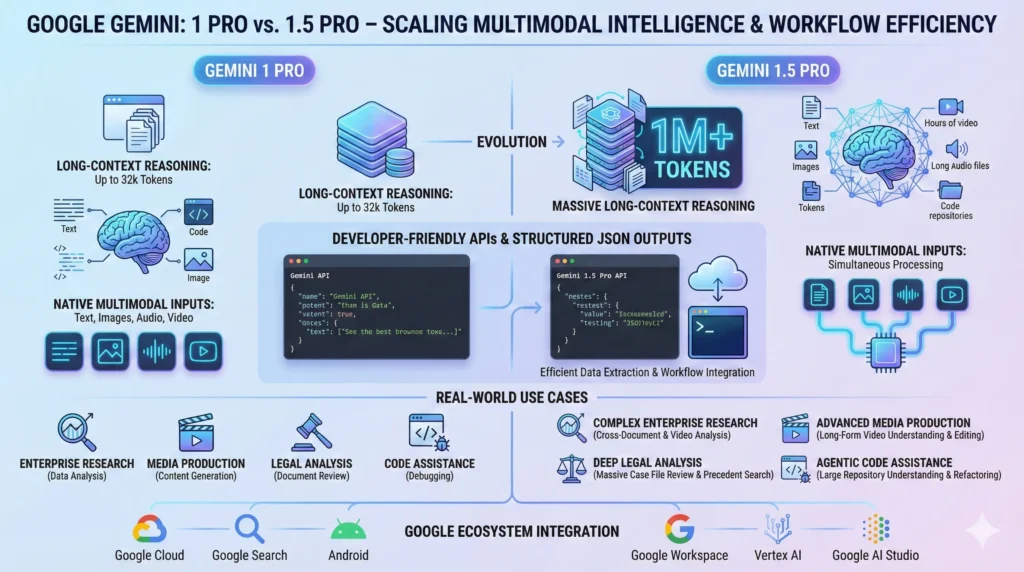
Use Google Gemini 1 Pro 2025, large language models have evolved from single-turn chat assistants into multimodal, long-context reasoning engines that are integrated into business workflows, research pipelines, and media production. The Gemini 1 Pro family — specifically Gemini 1 Pro and the upgraded Gemini 1.5 Pro — is positioned as Google’s answer to the need for coherent, persistent reasoning across very long inputs and mixed modalities (text, images, audio, video). Google Gemini 1 Pro Those models emphasize not only raw language competence, but also context scaling, deterministic structured outputs, and native multimodal fusion that let them serve as more than “conversational” agents: Google Gemini 1 Pro they act as document- and media-aware cognitive workhorses.
Google Gemini 1 Pro. From an NLP systems perspective, the key innovations that make Gemini Pro models relevant in 2025 are twofold. Google Gemini 1 Pro First, practical context-scaling mechanisms allow the models to consider orders of magnitude more tokens in a single runtime session than older models — enabling single-pass analysis of books, corpora, long legal briefs, or hours of transcripts. Google Gemini 1 Pro Second, native multimodal processing and developer-first output formats (structured JSON, function-calling primitives) make Gemini Pro attractive for production workflows where predictability and integration matter as much as raw qualit.
What Is Gemini 1 Pro & 1.5 Pro?
Gemini 1 Pro and Gemini 1.5 Pro are high-capability models in Google’s Gemini family. Bordered in NLP terms, they are large, highly optimized transformer-planted systems with additional system-level engineering (context management, anti, multimodal encoders, and builder I/O primitives) that set up:
- Long-context persistence: The Talent to visit extremely long input arrays with strategies to mitigate total and memory blast.
- Multimodal adjustment: Join cipher/portrayal for text, image, audio, and video frames, lax cross-modal thinking, and past.
- Deterministic structured outputs: Reply modes that favor machine-parseable outputs (JSON, tagged text, function calls) for programmatic drinking.
- Pipeline-native features: Taking, context segmentation, and function-calling abstractions that link with orchestration layers and over tools.
Gemini 1.5 Pro represents an engineering and model iteration that improves context scaling in mainstream releases, enhances native audio/video understanding, and optimizes runtime characteristics (parallel function calling, context caching) for production workloads.
Key Positioning Google Gemini 1 Pro
- Target: Enterprises, researchers, and developers who need deep document and multimodal reasoning.
- Role: Replace multi-step external pipelines with fewer single-pass workflows where feasible.
- Access patterns: Google AI Studio, Vertex AI, Gemini app, and APIs with tiered access.
Quick Summary
| Aspect | Gemini 1 Pro | Gemini 1.5 Pro |
| Context window | Very large — engineered for long contexts | Default larger windows (e.g., 128K) with mainstream 1M token availability |
| Multimodal | Text + image + basic audio | Text + image + improved audio + video frame reasoning |
| Best for | Research assistants, enterprise document analysis | Complex multimodal pipelines, deep-code reasoning |
| Developer support | JSON output, system prompts | JSON, function-calling, parallel execution |
| Trade-offs | Latency & cost at largest contexts | Improved scaling & caching, but still cost-sensitive |
Gemini 1 Pro — Key Features Explained
Massive Context Windows:
Technical framing. A “context window” is the model’s available sequence length for attention and conditioning. Traditional transformer decoders used quadratic attention over the context, which made very large windows prohibitively expensive. Practical long-context models combine architectural tricks and engineering patterns to reduce effective computational complexity:
- Sparse/local attention patterns (block-sparse, sliding windows) to limit quadratic blowup.
- Hierarchical encoders (chunk -> summary -> inter-chunk attention) to compress long passages into intermediate representations.
- Memory/state caching where computed chunk representations are stored and reused.
- Mixture-of-experts (MoE) and routing to selectively route computation to specialized submodules.
Gemini Pro integrates such Techniques so that end-users can submit large combined inputs (text + media) without manually chunking everything. The result is improved coherence across long documents and the ability to answer queries that require linking distant facts.
Why It Matters Google Gemini 1 Pro
For tasks like legal review, literature-level synthesis, or multi-hour meeting Summarization, being able to reference any part of the corpus in a single session reduces the error introduced by retrieval-and-stitching heuristics. It improves discourse-level consistency and reduces hallucination arising from split-context edge cases.
Native Multimodal Inputs
From an NLP and perception standpoint, multimodal capabilities require:
- Method-specific encoders (vision encoders, audio encoders, video frame extractors) that crop aligned latent aim.
- Cross-modal mind or blend layers that let modalities force each other all along understanding.
- Temporal grounding for audio/video, enabling timecodes and frame-based references.
Gemini Pro supports joint reasoning: you can feed a slide deck image, the transcript of a talk, and the raw audio and ask for a combined summary with timestamps and action items. That capability is particularly useful for media production and research workflows.
Developer-Friendly Outputs
Predictable output matters in production. Gemini offers deterministic structured modes:
- JSON schema enforcement: Instruct the model to produce exact keys/types.
- Function-calling primitives: The model returns machine-invokable outputs that can call external services.
- Token-level control: The ability to constrain tokens/grammar to reduce parsing errors.
This reduces the need for brittle NLP postprocessing; instead, applications can ingest outputs directly into pipelines, dashboards, or databases.
Improvements inGoogle Gemini 1 Pro 1.5 Pro
- Mainstream 1M token contexts with improved latency via caching and parallelism.
- Richer audio understanding (speaker diarization, intent detection) and video frame extraction pipelines.
- Parallel function-calling so models can orchestrate sub-tasks more efficiently.
- Context caching & reuse to amortize cost across repeated queries on the same corpus.
How Gemini 1 Pro Works
- Model core: A transformer-style network with optimizations (sparsity, MoE, specialized feed-forward networks) to increase compute efficiency and parameter utilization.
- Tokenizer & embedding: Robust subword or byte-level tokenization that handles multilingual corpora and multimodal inputs via embedding projection layers.
- Long-context modules: Chunking, ranked attention, and a memory hook that allow the model to indicate and finally attend to very long strings.
- Multimodal stack: Modality-clear cut frontends and fusion layers to adjust the image.
- I/O abstractions: JSON output schema enforcement, function-call APIs, and streaming outputs to integrate with orchestration systems.
- Runtime engineering: Sharded inference, model parallelism, context caching, and cost-aware routing (use smaller compute for cheap tasks, larger compute for deep reasoning).
Google Gemini 1 Pro Real-World Use Cases
Below are typical production archetypes where Gemini Pro models deliver value, explained in NLP and systems terms:
Enterprise Research Assistants
- Problem: Companies have thousands of reports, meeting notes, and data sources that require periodic synthesis.
- Gemini role: Ingest the corpora as long-context inputs or indexed caches, then produce entity-linked summaries, trend analysis, and recommended actions. Structured outputs are used to populate internal dashboards.
- NLP concerns: Need for source attribution, provenance tracking, and conservative summarization to avoid hallucinations.
Google Gemini 1 Pro Media & Production Workflows
- Problem: Editing and metadata generation for long-form video/audio is labor-intensive.
- Gemini role: Extract scenes, propose cuts, produce highlight reels, and annotate with timecodes by fusing transcript, audio features, and frame-level analysis.
- NLP/perception concerns: Speaker diarization accuracy, scene boundary detection, and time-aligned semantic labeling.
Google Gemini 1 Pro Legal & Compliance
- Problem: Compare long contract versions, extract risky clauses, and maintain traceable annotations.
- Gemini role: Ingest entire contract sets, compute diffs, flag nonstandard clauses, and output structured risk reports with source-page references.
- NLP concerns: Exact-match extraction, formal clause normalization, and conservative risk scoring.
Education & Tutoring
- issue: Create a syllabus and judgment from entire textbooks and recorded lectures.
- Gemini role: Follower of long lectures and textbooks into multi-level culture resources (summaries, spaced-repetition flashcards, quizzes) while preserving didactic rules.
- NLP sale: Granularity force, distractor generation for multiple-best questions, and content adjustment.
Code Assistance & Data Analysis
- Problem: Reason across large mono- and multi-repo codebases with long dependency graphs.
- Gemini role: Produce cross-file summaries, propose refactors, generate unit tests, and output machine-readable patch suggestions.
- NLP concerns: Schema-aware code generation, semantic AST reasoning, and deterministic outputs.
Strengths & Advantages Over Other Models
- Longest practical context: Gemini’s context scaling supports workflows that previously required retrieval and stitching.
- Native multimodality: Joint reasoning across visual, audio, and textual streams without external pre- or post-processing.
- Structured outputs: Designed for deterministic pipeline consumption; reduces brittle heuristics.
- Ecosystem union: A tight alliance with Google Cloud services, Drive, and Counter can simplify ingestion and cache.
Alarm:
Expanded context and multimodal skill come with latency and compute costs that must be budgeted for — caching, summarization, and mixed-precision reasoning are essential boosts.
Instruction Fidelity & Calibration
As with all generative models, instruction fidelity (following complex, multi-step instructions precisely) can be brittle. Best practices include formal prompt schemas, assertion checks, and validation steps.
Safety and Hallucinations
Long contexts increase the potential for spurious associations. Conservative scoring, provenance, and verification layers are necessary for high-stakes outputs (legal, medical).
Gemini 1 Pro vs Top Competitors
- Context length: Gemini emphasizes much larger practical contexts; competitors are improving, but may target different trade-offs.
- Multimodality: Gemini stresses native audio/video; GPT-4 variants focus heavily on text and images; Claude emphasizes instruction-safety.
- Structured outputs & developer I/O: All vendors provide mechanisms, but Gemini’s integration and caching features are engineered for pipeline use.
- Safety & adjustment trade-offs: Unlike vendors, tune orthodoxy vs. creativity; choose based on domain danger figure.
Benchmarks & Real-World Performance
Evaluation Metrics to Consider:
- Task-level accuracy: QA, extraction, summarization scores (exact match, ROUGE, F1).
- Long-range coherence: Discourse-level metrics measuring consistency across long documents.
- Multimodal grounding: Cross-modal retrieval and grounding precision.
- Latency & cost per token: Practical throughput measurements for production.
- Human evaluation: Domain experts scoring utility, hallucinations, and actionability.
Benchmarks show domain-dependent advantages; for long-context and multimodal tasks, Gemini 1.5 Pro often outperforms earlier models, but no model dominates all tasks. Rigorous A/B testing on task-specific datasets remains critical.
Pricing, Access & Plans
Pricing models are typically tiered: free/developer access for small contexts, subscription tiers for advanced models, and custom enterprise contracts for high quotas and SLAs. Expect usage-based billing where cost scales with compute and effective context length. In practice, plan pilots and measure cost per actionable result (not only cost per token).
How to Decide If Gemini 1 Pro Is Right for You
Consider these NLP/system questions:
- Do you need deterministic machine-readable outputs for integration?
- Is the budget available for potentially higher compute costs for long-context inference?
If the answers are yes, Gemini Pro is a strong candidate. Otherwise, a smaller, cheaper model plus retrieval may be the optimal solution.
Pros & Cons Google Gemini 1 Pro
Pros
- Practical long-context processing
- Native multimodal fusion
- Deterministic and structured outputs
- Strong integration with the Google ecosystem
Cons
- Higher latency & compute cost at extreme scales
- Some features geared to premium tiers
- Benchmarks vary by task
Common Myths & Misconceptions
- Myth: A 1M token window makes chunking obsolete.
Truth: Chunking and hierarchical summarization still help control cost and improve quality for extremely large corpora. - Myth: Gemini always beats GPT-4.
Truth: Model choice should be task-driven — each model has strengths and trade-offs.
FAQs Google Gemini 1 Pro
A: Gemini Pro models support very large context windows — default 128K, up to 1 million tokens in many rollouts, and 2M in developer previews.
A: “Better” depends on the use case. Gemini leads for long-context and multimodal tasks; GPT-4 may be stronger for instruction fidelity in some cases.
A: Cost scales with compute — 1M+ token calls are more expensive and slower. Pilot test to estimate.
A: Yes — Gemini supports JSON and structured output modes.
A: Sign up for Google AI Studio, start with the free tier, then scale to pay-as-you-go or Advanced/Pro plans.
Conclusion Google Gemini 1 Pro
Google Gemini 1 Pro and 1.5 Pro represent a major leap in 2025 AI, excelling at long-context reasoning and multimodal processing. They are ideal for enterprises, researchers, and developers needing deep insights from massive text, audio, video, and image inputs. While powerful and integrated within the Google ecosystem, users should consider cost and latency for extremely large tasks. For workflows requiring structured outputs, complex analysis, or multimodal understanding, Gemini Pro models are among the top choices in 2025.