
ChatGPT vs Gemini 1.5 Flash (2026) — 1M Tokens vs 256K: What Most Teams Miss
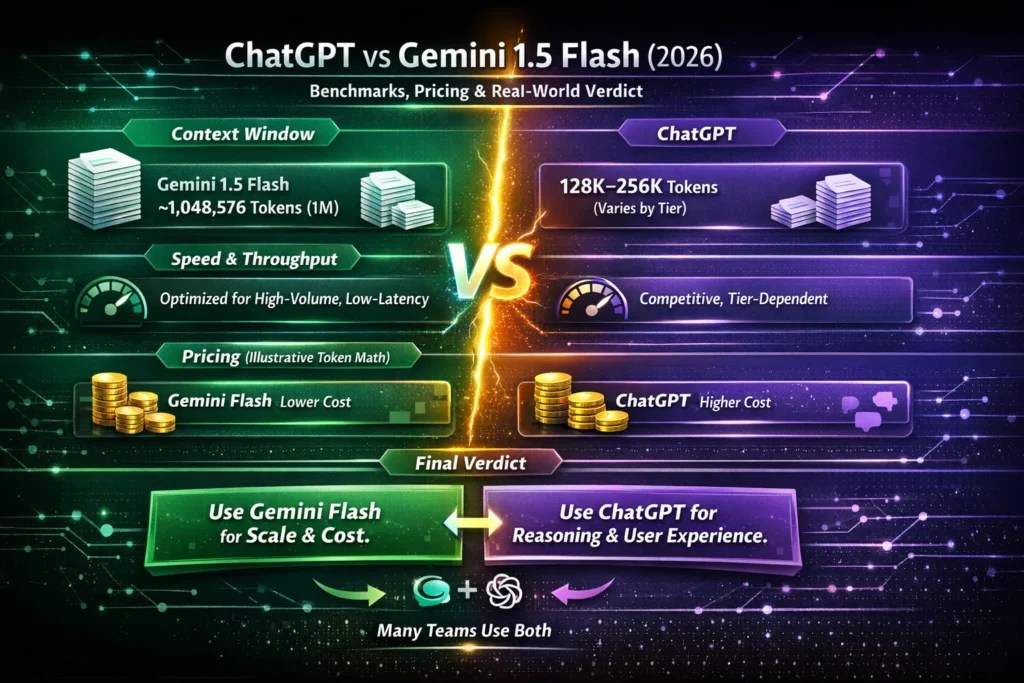
- ChatGPT vs Gemini 1.5 Flash (2026) — Use Gemini Flash for massive-context, cost-sensitive pipelines; use ChatGPT for creative reasoning and UX polish.
- If you’re confused by token limits, latency, and spiraling costs, this guide compares real benchmarks, cost math, migration tips, and prompts so you’ll know which model saves money, scales without heavy engineering, and delivers clarity your users demand. Massive-document processing (1M+ tokens): Gemini 1.5 Flash usually wins.
- Creative writing, plugins, and premium reasoning: ChatGPT often wins.
- Cost-sensitive, high-throughput deployments: Gemini 1.5 Flash tends to be cheaper.
- Balanced reasoning + mature tools & ecosystem: ChatGPT remains a strong choice.
Short takeaway: Use Gemini 1.5 Flash for scale and token-dense workloads; use ChatGPT for nuanced reasoning and user-facing experiences. Many teams run both in the same stack and route tasks to whichever model fits the objective.
Which Model Actually Saves You Money and Engineering Time?
| Feature | ChatGPT | Gemini 1.5 Flash | Best for |
| Context window (real-world tiers) | Large (many practical tiers in 2026 include 128K–256K tokens) | ~1,048,576 tokens in Flash-class variants | Long-document workflows |
| Latency | Competitive; depends on tier | Tuned for very low latency & very high throughput | Real-time chat at scale |
| Pricing (per million tokens) | Higher for flagship reasoning models (varies by tier) | Often lower on Flash tiers; built for scale | Cost-sensitive large apps |
| Ecosystem & plugins | Very mature plugin & tooling ecosystem | Deep Google Cloud integration (Vertex AI) | UX/tooling: ChatGPT; Cloud-native scale: Gemini Flash |
Who Makes these Models?
OpenAI and Google
These are the organizations behind the two model families. After this, I’ll use the short names “ChatGPT” and “Gemini 1.5 Flash.”
Why this comparison matters
Choosing the wrong model for a product can cost engineering time, increase latency, and balloon monthly cloud bills. Two dimensions tend to dominate decision-making:
- Context capacity — how many tokens you can feed in a single inference (prompt + system + history + expected output). This determines whether you can process whole books, whole long transcripts, or massive codebases without extensive chunking.
- Cost & throughput at scale — per-token prices and latency characteristics. If you expect thousands of RPS (requests per second) and millions of tokens per month, tiny per-token differentials compound rapidly.
This guide is practitioner-facing: concrete benchmarks, example prompts, migration steps, risk/guardrail patterns, and a persona-based final verdict so you can make an engineering decision rather than guess.
Deep dive: context windows and practical consequences
What is a context window in NLP terms?
A context window is the effective receptive field of a transformer at inference time: how many input tokens (and the reserved tokens for the model’s output) the model can attend to in one forward pass. In transformer-based models, attention complexity scales with sequence length (O(n²) for vanilla attention), but architectural and engineering optimizations (sparse attention, flash attention kernels, windowed attention, memory-compressed attention) shift the practical trade-offs. A bigger window reduces the need for external document stores, chunking strategies, and stitching logic.
Why larger contexts matter in applied
- One-shot global reasoning: You can give the model an entire corpus slice and ask cross-document questions without expensive retrieval or concatenation logic
- Reduced stitching errors: Chunking + stitching often loses inter-chunk coherence and requires additional merge passes; large windows eliminate many of these failure modes.
- Simpler prompt engineering: You can keep richer system instructions and more of the conversation history while still reserving enough tokens for a substantive reply.
- Agentic pipelines: If your pipeline spins up many chained calls with tool-using agents, larger windows let you maintain the agent planning trace without offloading to external storage as frequently.
Example: tokens in the wild
- One hour of high-density meeting transcript ≈ 75k–120k tokens (depends on speech cadence and transcription verbosity).
- A medium-sized codebase for review ≈ , 200k–400k tokens (source files, comments, and infra).
- 1M words ≈ ~1.3M tokens (language dependent), so a 1M-token window allows you to do very large slices at once.
Practical point: If your app frequently needs more than a few hundred thousand tokens in a single pass, a Flash-class model that supports ~1,048,576 tokens materially simplifies engineering.
Benchmarks — Realistic Experiments
Below are practical tests many teams run; they focus on usability and measured outcomes (latency, cost, output quality). Results will vary by dataset and prompt engineering; these are empirical, illustrative summaries.
Test 1 — Long-transcript summarization
Task: Structured summary, actions, quotes.
- Gemini 1.5 Flash: Ingests whole transcript in one request, streams output, fast turnaround. Produces concise executive TL; DRs and clear action items. Tends to be higher-level, sometimes less granular unless prompted to expand.
- ChatGPT: Often chunk-and-stitch unless on very large special modes. Produces more nuanced human-like summary voice and better rhetorical phrasing. Stitching required extra engineering.
Verdict: Gemini Flash = scale + speed; ChatGPT = deeper tonal finesse and human polish.
Test 2 — Multi-file codebase reasoning
Task: Generate architectural refactor plan and PR breakdown.
- Gemini Flash: Scans repo at scale, gives fast high-level mapping and dependency graph summaries.
- ChatGPT: Produces more careful prose around why changes are beneficial and writes cleaner instrumentation and unit-test examples. More conservative suggestions for backwards compatibility.
Verdict: Use Gemini Flash for scanning and mapping; use ChatGPT for writing developer-facing docs and carefully-worded migration steps.
Test 3 — Multi-step formal reasoning and math
Task: Proofs, algorithmic derivations, multi-step debugging.
- ChatGPT: Slight edge for structured chain-of-thought style explanations and stepwise reasoning when configured for verbose reasoning.
- Gemini Flash: Accurate and fast; sometimes more concise and needs prompt nudges for verbose justifications.
Verdict: Slight advantage to ChatGPT for explainability and human-readable derivations.
Test 4 — Creative long-form narrative
Task: Maintain voice, character, and scene over many pages.
- ChatGPT: Superior at nuanced character voice, stylistic variation, and maintaining plot beats when guided with system instructions.
- Gemini Flash: Strong but sometimes leans towards functional, less lyrical prose.
Verdict: ChatGPT wins for literary and marketing creative work.
Test 5 — High-volume short-chat throughput
Task: 10k small prompts (short chat replies), measure latency & cost.
- Gemini Flash: Typically faster average latency and lower per-token cost on Flash tiers; well-tuned for high throughput.
- ChatGPT: Stable and good latency, but costs can be higher for equivalent throughput depending on the chosen model.
Verdict: Gemini Flash for very high-volume, cost-sensitive workloads.
Pricing & cost examples — how to think about token math
Important: pricing changes rapidly. Treat these numbers as illustrative token-math — always check live pricing for billing.
Basic math primer
- Monthly tokens = tokens per request × requests per month.
- Cost = (Monthly tokens) × (cost per token).
- When comparing costs, include engineering overhead (stitching, retrieval cost, additional inference calls), not just per-token price.
Example A — 100k tokens per day
- 100k tokens/day → 3M tokens/month.
- If Model A costs $10 per 1M tokens → $30/month.
- If Model B costs $1.50 per 1M tokens → $4.50/month.
- Small per-token differences multiply at scale.
Example B — Indexing a 1M-word archive
- 1M words ≈ 1.3M tokens.
- With a 1M-token context, you can avoid heavy chunking for large slices, reducing API calls and orchestration complexity.
Engineering insight: Even when per-token prices are similar, fewer total API calls reduce latency, error surfaces, and operational complexity — which has monetary cost.
When to choose each model — a compact decision tree
Choose Gemini 1.5 Flash if you:
- Need huge context windows for single-pass processing (legal docs, long transcripts, code monorepos).
- Require low-latency streaming at very high throughput.
- Target cost-sensitive, large-scale automation and indexing.
- Need deep integration with Google Cloud / Vertex AI for deployment.
Choose ChatGPT if you:
- Need premium creative writing, tone control, and an established plugin ecosystem.
- Want refined step-by-step reasoning and interactive polishing for user-facing experiences.
- Rely on third-party plugins or existing integrations in the ChatGPT ecosystem.
Hybrid approach (recommended): Use Gemini Flash as a throughput and scanning layer, and use ChatGPT for final reasoning, human-facing polish, and multi-step explanations. Abstract the model layer so you can route per task.
Integration & migration checklist — an engineer’s playbook
If you plan to test or switch models, follow these steps:
- Abstract the model layer. Create a single interface that your product uses (adapter pattern) so swapping models is straightforward.
- Normalize prompts. Centralize templates and version them. Maintain per-model variants for system tokens and instruction style.
- Token budgeting. Build monitoring and caps to avoid surprises; track tokens per request, per user, per feature.
- Retry & rate-limit logic. Add exponential backoff and contextual rate limiting.
- A/B tests. Run experiments on real traffic slices; evaluate latency, cost, hallucination rates, and user satisfaction.
- Hallucination monitoring. Add checks, verification steps, and ground-truth compare pipelines for high-risk outputs.
- Logging & explainability. Record prompts, responses, and metadata for debugging and QA.
- Human-in-the-loop. Start with human validation for initial production rollouts (e.g., first 1,000 outputs).
- Gradual ramp-up. Move from canary → 10% → 50% → full traffic as metrics stabilize.
- Post-deployment audits. Regularly re-evaluate quality as models are updated.
Risks, limitations & guardrails
- Hallucinations persist. Even large-context models can invent facts. Add verification for high-stakes outputs.
- Context ≠ memory. Context windows are not a persistent database. Use canonical stores for long-lived facts and reference them through retrieval.
- Privacy & compliance. Large context requests may include sensitive data. Make sure data governance and redaction are in place.
- Cost & lifecycle. Models and pricing change often; monitor for deprecations and new releases.
- Performance varies by task. One model that excels at summarization may be weaker at creative style or complex math — measure on your dataset.
- Operational complexity. Very large windows sometimes require special client-side libraries or increased compute; ensure your infra supports the chosen model’s throughput.
moving summarization from ChatGPT to Gemini Flash
- Baseline measurement: Collect a sample set (10–20 transcripts). Measure token size and current performance (latency, accuracy, human satisfaction).
- Adapter & prompt translation: Implement a thin adapter to translate your ChatGPT prompt to Gemini Flash format. Normalize system instructions.
- Parallel runs: Run both models on the sample set; compare outputs on objective metrics (precision for action items, recall for decisions, and human-rated quality).
- Human-in-loop: For the first 1,000 outputs on Gemini Flash, add human validation and feedback loops.
- Canary rollout: Deploy Gemini Flash to 10% traffic; monitor latency, costs, and user satisfaction closely.
- Optimization: Tune prompts, add temperature/penalty adjustments, and refine post-processing.
- Full rollout: Gradually increase traffic if metrics meet the bar.
Example cost-savings scenario
If you have 500k users, each generating 200 tokens per session, 4 sessions/month:
- Monthly tokens = 500k × 200 × 4 = 400M tokens.
- If ChatGPT costs $10 / 1M tokens → $4,000/month.
- If Gemini Flash costs $1.50 / 1M tokens → $600/month.
- Savings: $3,400/month on illustrative rates.
Note: These are example rates — always plug in official pricing.
Tasks to test first
- Long-document summarization (sample >200k tokens).
- High-volume short-response service (chat replies).
- Codebase scanning and refactor plan.
- Creative copy generation for marketing.
- Math-heavy reasoning tasks.
Track: latency, cost per session, human editing overhead, and subjective user satisfaction.
FAQs, Common Mistakes & Smart Optimization Tricks
A: Yes — Gemini Flash-class models are documented to support ~1,048,576 tokens for certain variants; that enables very large single-pass inputs.
A: Depends on the task. ChatGPT often produces clearer multi-step reasoning and more human-calibrated language. Gemini Flash trades some stylistic nuance for scale and speed.
A: Often, Gemini Flash has lower per-million-token rates on Flash tiers, making it cheaper for huge workloads. Confirm live pricing and run ROI math for your workload.
A: Yes — with a model abstraction layer and centralized prompt templates. A/B testing and gradual rollouts are recommended.
A: Yes. Both models can hallucinate and make mistakes. For critical decisions, include verification and human review.
Final Verdict — Which Model Should You Choose in 2026?
- If your product processes very long documents or needs extreme throughput and low-cost token handling, try Gemini 1.5 Flash.
- If your product prioritizes refined creative output, polished conversational UX, or a mature plugin ecosystem, pick ChatGPT.
- Most teams benefit from a hybrid approach: scan and index at scale with Flash, then use ChatGPT for the last-mile reasoning and user-facing polish.