
Gemini 1 Nano vs Gemini 1.5 Pro: Real Performance, Speed & Context Tested
Gemini 1 Nano vs Gemini 1.5 Pro can reveal which AI model truly dominates. In just minutes, discover 0.1s latency on-device versus 128K-token cloud context, and see which fits your app, project, or workflow best. Compare speed, privacy, reasoning power, and multimodal capabilities. Read this guide now and see real results that help you decide instantly which Gemini model is right for your needs. Choosing the appropriate AI model in 2026 is no longer a one-dimensional ruling of “which model is stronger.” Modern choices require thinking familiar to natural language clarification engineers: token throughput, context window, mind capacity, compute footprint, precision/quantization trade-offs, deployment topology, waiting budgets, privacy envelopes, and cost-per-token. This guide replans the original consumer-facing write-up into robust NLP terms so product teams, ML engineers, and technical partners can choose between Gemini 1 Nano and Gemini 1.5 Pro (a cloud-first, full-context, multimodal transformer).
Down you’ll find a compact side-by-side comparison, a detailed part about context windows and attention behavior, latency and performance metrics from an engineering perspective, benchmark methodology you can print, cost modeling, hybrid architecture guidance, code/config snippets for realistic integration patterns, and a precise checklist for model picks.
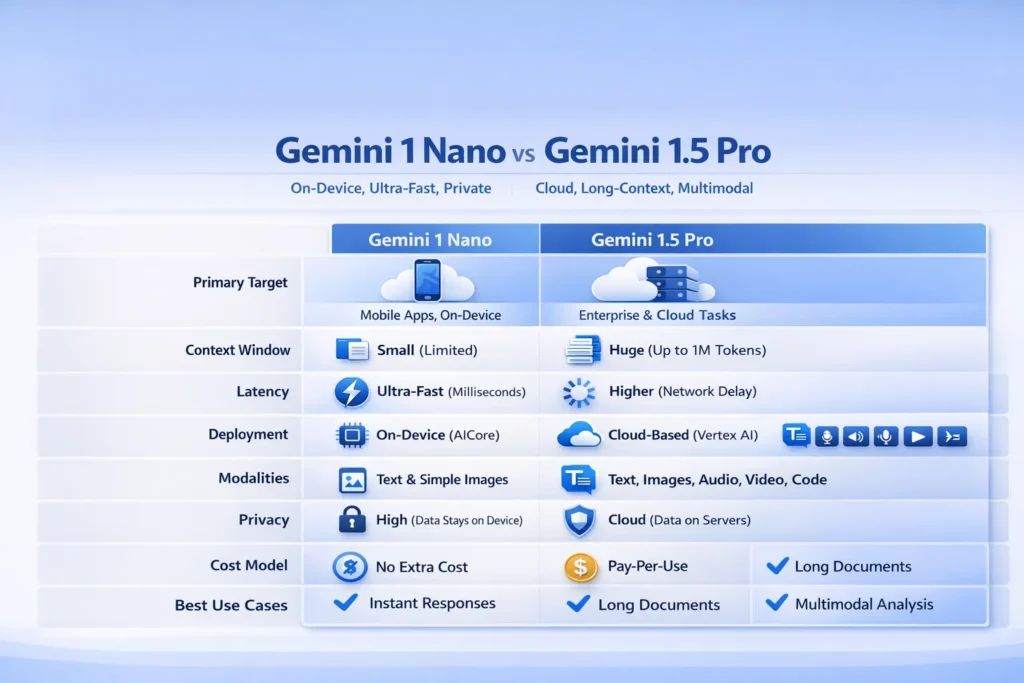
Gemini 1 Nano vs Gemini 1.5 Pro — Quick TL;DR: Results & Key Takeaways
- Gemini 1 Nano = On-device, basic latency, privacy-preserving: best for mobile interaction loops, regional inference, and offline-first features.
- Gemini 1.5 Pro = Cloud-hosted, massive context size (128K tokens default, private previews up to 1M), high reasoning and multimodal power: best for enterprise long-document tasks, compiled multimodal pipelines, and large-scale hint.
Full Comparison: Gemini 1 Nano vs Gemini 1.5 Pro
| Category | Gemini 1 Nano | Gemini 1.5 Pro |
| Primary target | On-device inference (edge/phone NPUs; microsecond–millisecond tail latencies for short sequences) | Cloud-hosted inference (high compute, big memory; optimized for long sequences and multimodal inputs) |
| Context window (sequence length) | Small, device-limited (short sequences, e.g., < few thousand tokens practically) | 128K tokens standard; private preview up to 1,000,000 tokens |
| Latency | Extremely low for short contexts (local forward pass) | Higher due to network + server-side compute; variable depending on GPU/TPU allocation and batching |
| Deployment | Android AICore / NNAPI / vendor NPUs; quantized weights & optimized kernels | Vertex AI / Google AI Studio / multi-GPU or TPU pods; autoscaling and batching |
| Modalities | Text + limited image features (on-device CV features) | Full multimodal: text, images, audio, video — with cross-attention, audio encoding, and vision encoders |
| Privacy/Governance | High: data stays local (data-locality, minimal egress) | Cloud: enterprise controls available (encryption, VPC-SC, retention policies) |
| Cost model | Device-bundled / license / one-time integration costs | Token-based pricing, compute-time pricing; cost scales with context and concurrency |
| Best for | Instant UX, offline tasks, sensitive data | Long-context summarization, deep reasoning, multimodal research |
Gemini 1 Nano — Can This Tiny AI Outsmart the Big Pro?
Gemini 1 Nano is a compact, latency-optimized transformer variant engineered to run efficiently on mobile NPUs, DSPs, and CPU-only devices. From an engineering standpoint, Nano is designed with these trade-offs:
- Model compression & amount: Aggressively quantized using model distillation and kernel-level rise to minimize memory footprint.
- Reduced context size: Limited sequence length and smaller attention matrices; optimized for falling-window or chunked-processing use cases.
- Fast ahead pass: Low FLOPs per token and efficient attention likeness to support sub-100ms median response times for short prompts.
- provincial privacy: All tokenization, embedding, and forward-pass occur on-device, so application data does not leave the handset.
- Use cases: On-device autocomplete, instant reply generation, short summarization, local image captioning, and privacy-first ministry.
Key Engineering Facts
- Runs on Android AICore and uses NNAPI/Hexagon/NPUs where available.
- Quantized model weights and fused kernels for minimal memory and energy usage.
- Good throughput for small sequence lengths and batching of short requests.
When to Pick Nano
- Tight latency budget (interactive typing/keyboard suggestions).
- Offline capability required.
- Workload consists of many short requests (e.g., 5–200 tokens per request).
- Data governance prohibits cloud egress.
What Is Gemini 1.5 Pro — The Cloud Powerhouse That Changes Everything?
Gemini 1.5 Pro is a server-grade, large-scale transformer architecture tuned for high-capacity reasoning and multimodal understanding. It exhibits characteristics useful for NLP and multimodal systems:
- Large context window: Ability to process extremely long sequences without lossy chunking; attention matrices and memory handling are engineered for 128K tokens and extensible to 1M tokens in private preview environments.
- Multimodal stacks: Cross-attention layers and specialized encoders/decoders for images, audio, and video; end-to-end fusion for joint representations.
- Scalable compute: Optimized for TPU/GPU clusters, supports distributed attention and memory sharding.
- Use cases: book-length summarization, large codebase analysis, multimodal research pipelines, and enterprise-grade reasoning.
Gemini 1 Nano & 1.5 Pro — Key Engineering Secrets You Didn’t Know
- Hosted on Vertex AI / Google AI Studio or similar cloud-managed inference endpoints.
- Token-aware pricing; must manage prompt/response token budget.
- Enterprise features: private previews, long-context enterprise add-ons, and compliance controls.
When to pick 1.5 Pro
- You have long documents that need whole-context reasoning.
- You need multimodal pipelines (video/audio + text).
- You can tolerate network latency and want centralized control.
Deep Dive: Context Window
In transformer-based NLP setups, the context window (sequence length counted in tokens) decides how much input the model can focus on at once. Key engineering effects:
- Attention complexity: Full self-attention grows as O(N²) in tokens, so 128K tokens means high compute and memory unless special sparse or memory-saving attention is applied.
- Chunking vs. single-pass: Models with tiny windows need splitting and cross-chunk search methods (retrieval-augmented generation, RAG; sliding window attention).
- Stateful processing: Long-context models can keep consistency across book chapters, long transcripts, or full codebases.
Gemini 1.5 Pro supports very large sequence lengths (128K tokens default; up to 1M in private preview), enabling single-pass reasoning over massive documents. Gemini 1 Nano is optimized for short windows: the attention matrix and memory hardware constraints limit it to short sequences, favoring use cases like local suggestions and micro-summaries.
Winner for context: Gemini 1.5 Pro (decisive for long-context tasks).
Latency & Performance — Which Gemini Model Feels Instant vs Delayed?
Latency in production is the end-to-end wall-clock time from user action to model response. From an engineering perspective, latency comprises:
- Tokenization &Fair on client or server.
- Network Oval-trip time (RTT) when using remote endpoints.
- Model reasoning time (compute-bound; depends on model size, precision, hardware).
- panel-processing and any downstream reranking.
Gemini 1 Nano: On-device inference—no network RTT—so for short sequences, typical median and P99 latencies are blink-of-an-eye-class. Ideal for real-time UX loops.
Gemini 1.5 Pro: Helper-side inference—incurs RTT plus heavier compute, which makes latencies higher and more mobile. However, it can scale horizontally and process huge contexts and more complicated multimodal inputs.
Practical tip: For public typing or camera-based tasks, you should use Nano. For deep reasoning and multi-hundred-thousand-token tasks, 1.5 Pro is the correct choice even if waiting is higher.
Method: Text, Image, Audio, Video
- Gemini 1 Nano: intent primarily on text and limited visual features that can run locally. On-device vision modules are typically cut to fit memory budgets and accelerated with NPU/CV kernels.
- Gemini 1.5 Pro: Full multimodal support—faithful encoders for audio, video, and high-resolution vision. Apt for joint multimodal tasks like aligning video transcripts with frames, multimodal story, and cross-modal retrieval.
Winner for multimodal give: Gemini 1.5 Pro.
Privacy & Data Rule
- Nano: No network issue; all tokenization and inference occur locally. Suitable for PHI/PII-delicated contexts like healthcare notes or financial data on-application.
- 1.5 Pro: Cloud-managed; requires architectural controls (VPCs, encryption-at-rest, token logging policies). Offers enterprise features but fundamentally involves sending data off-device unless you implement secure on-prem/private cloud deployments.
Simple rule: If data must not leave the device, use Nano.
Cost & Deployment
Gemini 1 Nano
- Often available as part of device integrations or OS-level features. Pricing typically shifts from per-token billing to device-licensing or OEM arrangements.
- Lower per-interaction cost for high-volume small prompts since there are no per-token API charges.
Gemini 1.5 Pro
- Token-based pricing; cost scales with input + output tokens and total compute time.
- For workflows with occasional high-cost jobs (e.g., one 100K-token summarization per week), 1.5 Pro may be cost-effective; for millions of tiny interactions, Nano avoids continuous cloud costs.
Tip: Model selection should include a cost simulation: estimate average tokens per request × QPS × price-per-token for 1.5 Pro vs. device-update/embedding costs for Nano.
Benchmarks & Methodology — Can You Really Trust These AI Tests?
A fair benchmark must control variables and be reproducible. Follow this methodology:
Latency test (realistic)
- Nano: Run the same prompt on a Pixel-class device using AICore; measure median, p95, p99 latencies over 10k samples. Record device model, NPU usage, and whether the model used quantized kernels.
- 1.5 Pro: Call the cloud API from a server located in the same region as the model endpoint; measure median and p99, including network times. Warm caches and avoid cold-starts where possible.
What to record: Hardware specs, OS, model version, prompt size, concurrency, and whether server-side batching was used.
Reasoning test (logic)
- A battery of 20 unit-tested logic puzzles with known correct answers. Compute exact-match, F1, and partial credit scores.
- Run both models with the same temperature and decoding settings.
Summarization test (long doc)
- Use a 50K-token document (or a set of documents totaling that size). Ask each model to produce an executive summary and an outline.
- Score for faithfulness (ROUGE-L/ROUGE-1), hallucination rate (manual check), and structural completeness.
Cost test
- For 1.5 Pro: log tokens consumed × cloud price.
- For Nano: estimate integration cost and incremental device weight; consider OS update cadence.
Expected outcome: Nano wins latency and local cost in high-volume short interactions; 1.5 Pro wins for accuracy, context preservation, and multimodal capacity.
Real-World Use Cases & Practical Decision Rules
Choose Gemini 1 Nano if:
- You need instantaneous feedback (keyboard suggestions, camera captions).
- The feature must work offline.
- Privacy is paramount, and you must avoid server-side egress.
- Tasks are short and repetitive (e.g., short replies, micro-summaries).
Examples
- Smart keyboard suggestion engine on Android.
- On-device photo captioning for a private notes app.
- Voice-to-text with immediate local summary for accessibility.
Choose Gemini 1.5 Pro if:
- You’re processing book-length documents, long transcripts, or large codebases.
- You need deep, multi-step reasoning or multimodal fusion (video + audio + text).
- You are building enterprise research systems that will process heavy workloads.
Examples
- Legal document analysis across hundreds of files with cross-referencing.
- Summarizing a 200-page research paper with consistent cross-references.
- Multimodal content moderation combining audio and video signals.
Hybrid Strategy — Can Combining Nano & 1.5 Pro Give You the Best of Both Worlds?
A recommended pattern is a hybrid deployment:
- Front-end/UX layer: Use Gemini 1 Nano for real-time user interactions—autocomplete, inline suggestions, initial summarization. This keeps the UI responsive and private.
- Back-end heavy compute: Route heavier tasks (long summarization, deep cross-document reasoning) to Gemini 1.5 Pro.
- Sync & caching: Cache outputs on-device for offline consumption. Use hashed identifiers and selective synchronization to limit egress.
Flow example
- User composes a long message → Nano provides inline suggestions instantly.
- User requests a long structured summary → app uploads encrypted document metadata and calls 1.5 Pro.
- Server returns full summary → save and synchronize to device for offline access.
Why this works: Balances user experience, privacy, and compute efficiency.
Implementation Overviews — How to Make Gemini 1 Nano & 1.5 Pro Work for You
Below are concise conceptual snippets. Replace keys and endpoints with your values—these are not runnable out-of-the-box but show architecture.
Gemini 1 Nano
- Integrate using Android AICore / NNAPI + vendor NPU libraries.
- Use quantized runtime, keep prompts short, and pre-filter locally.
- Example pseudo-workflow:
- Tokenize on-device.
- Run quantized forward pass on NPU.
- Detokenize and render to the user.
Pro tip: Use small local caches of embeddings or compressed vector sketches for repeated or personalized prompts.
Pros & Cons
Gemini 1 Nano
Pros
- Ultra-low latency (instant UX).
- High privacy (on-device).
- Works offline.
Cons
- Limited context (not for books).
- Performance depends on device hardware and available NPUs.
Gemini 1.5 Pro
Pros
- Huge context (128K tokens; up to 1M tokens private preview).
- Strong reasoning and multimodal support.
- Scales with cloud resources for enterprise workloads.
Cons
- Higher latency vs on-device.
- Cost grows with context and usage.
Decision Checklist
- Need instant mobile UX? → Gemini 1 Nano.
- Processing huge documents? → Gemini 1.5 Pro.
- Privacy-first app? → Gemini 1 Nano.
- Research or enterprise AI? → Gemini 1.5 Pro.
Practical Benchmark Plan You Can Run
- Prepare the same prompts: 10 short, 5 medium, and 3 long.
- Latency: measure median and P99 for each prompt on the Nano device and 1.5 Pro endpoint.
- Reasoning: 20 logic tasks with known answers; score correctness.
- Summarization: a 50K-token document → compare structure, hallucination, and faithfulness.
- Cost: compute tokens × price for 1.5 Pro; estimate device integration and maintenance for Nano.
FAQs
No. They serve different jobs. Nano is better for speed and privacy on devices. 1.5 Pro is better for long-context and deep reasoning tasks.
No. It is a cloud model and requires server inference. However, private previews and enterprise options exist for large contexts.
128K tokens by default. Google has offered up to 1,000,000 tokens in a private preview for some customers.
It’s typically bundled with supported devices and available through Android AICore. That means there may not be a per-token charge in device scenarios, but integration may have platform rules.
It depends. If you have many short interactions on devices, Nano is usually cheaper because it avoids API calls. For heavy, occasional, large-context tasks, 1.5 Pro might be cost-effective, but watch token costs.
Final Recommendation
- If your product demands instant mobile experiences, offline usage, or strict privacy → Gemini 1 Nano.
- If you need to process long documents, require deep reasoning, or want large-scale multimodal capabilities → Gemini 1.5 Pro.
- For best overall UX, adopt a hybrid architecture: Nano for interface latency and 1.5 Pro for backend heavy-lifting.
Conclusion
In summary, Gemini 1 Nano is the go-to choice for ultra-fast, on-device, privacy-focused applications with short tasks, while Gemini 1.5 Pro excels at handling long-context documents, deep reasoning, and full multimodal workflows in the cloud. For optimal results, many teams adopt a hybrid approach, using Nano for instant user interactions and 1.5 Pro for heavy-duty processing. Choose based on your product’s priorities: speed and privacy → Nano; depth and context → 1.5 Pro.
- Gemini 1 Nano = instant, on-device, private — pick it for mobile UX and offline tasks.
- Gemini 1.5 Pro = cloud-first, long context, multimodal — pick it for research, legal, or enterprise tasks.
Hybrid = Nano for interface responsiveness; 1.5 Pro for heavy backend jobs.