
Introduction
GPT-2 vs GPT-3 can reveal which model truly fits your use case and budget. In just 5 minutes, achieve up to 70% cost savings, faster inference, and smarter deployment decisions. Read the comparison, apply the insights, and see real results in 2026. Choosing the right language model in 2026 is an engineering and product decision as much as it is a research one. Mere framework counts no longer answer whether a model is “better” for your product—teams must weigh latency, cost per request, data governance, fine-tuning involvement, inference stability, and integration effort.
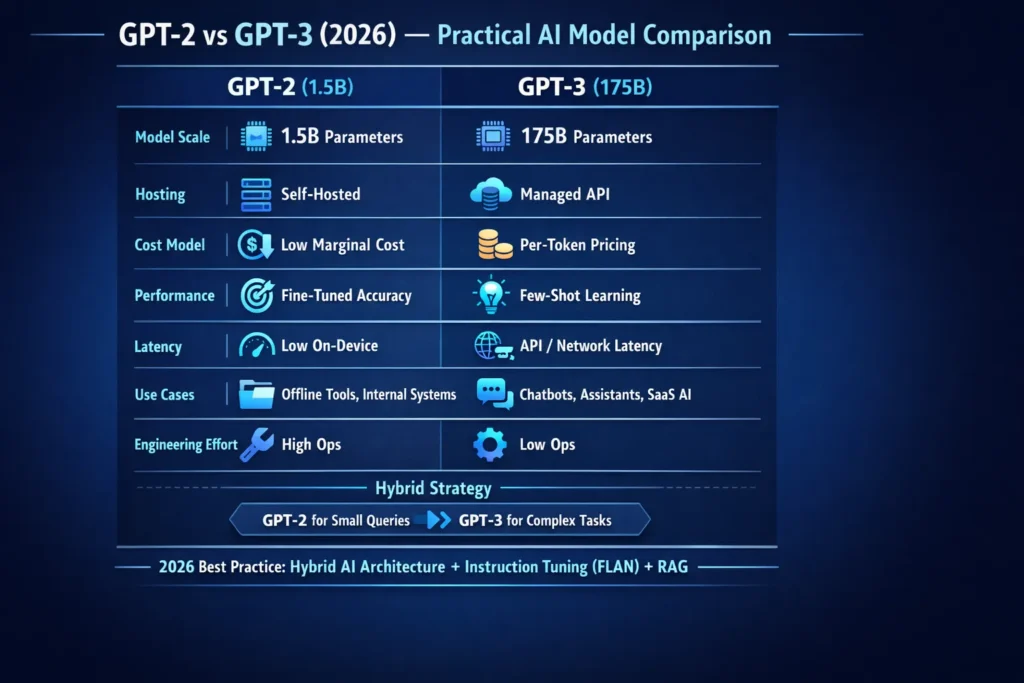
This guide compares GPT-2 (1.5B parameters) and GPT-3 (≈175B parameters) in hands-on, reproducible terms for practitioners who need to ship reliable NLP systems. You’ll get a concise description of what each model is, how scaling affects emergent behaviors, practical prompts to run A/B tests, TCO heuristics for self-host vs managed API, and an actionable migration checklist. We’ll feature instruction-tuning (the FLAN paradigm), retrieval-augmented generation (RAG) patterns for factual accuracy, and hybrid routing planning that lets teams get near large-model performance while keeping most traffic cheap. At the end, you’ll find a shift plan, an engineering checklist, and appendices you can copy into your test harness. The aim: give pragmatic charge and the exact things to measure in your stack, not marketing fluff.
Who Wins Where? The 30-Second Verdict by Use Case
If you set up on-prem privacy, low incremental cost at very high throughput, or offline operation, GPT-2 (1.5B) is the practical choice. It’s open-weight, easy to attractively tune, and runs on modest GPU hardware. For narrow, high-volume pipelines—document recap, embedded assistants, and deterministic transformation tasks—GPT-2 with instruction-tuning and RAG often gives the best price/act.
If you need robust few-shot learning, higher baseline eloquence across varied domains, or you prefer a managed experience with safety tooling and insured scaling, GPT-3 (≈175B) wins. GPT-3 produces more coherent long-form text and stronger in-context learning with fewer engineering tricks, making it ideal for general-purpose customer-facing assistants, creative generation, and teams that don’t want to operate GPU arrays.
Nearly all groups benefit from blended directing: direct everyday requests to a refined GPT-2 setup (or that prompt-adjusted compact model) and forward premium varied requests to GPT-3 (or a prompt-adjusted massive model). Prompt-refinement (FLAN-like) and RAG shrink the performance divide, so prioritize a compact-model adjustment initiative before locking into constant API usage.
GPT-2 or GPT-3? Unpacking the AI Powerhouse Battle
GPT-2
- Release year: 2019
- Parameters: up to 1.5B (GPT-2 XL)
- Weights: publicly released — downloadable and fine-tunable
- Key traits: open weights, straightforward to self-host and fine-tune, cost-effective for high-volume narrow tasks
GPT-3 (at a glance)
- Release year: 2020
- Parameters: ~175B (original flagship)
- Weights: Historically API-accessible only; flagship weights not open-sourced in the original release
- Key traits: Strong few-shot in-context learning, higher baseline fluency and coherence for long-form outputs, often provided as a managed API with provider safety/monitoring features
How GPT-3 Improved on GPT-2 — Technical Overview
Model scale & Architecture
The most salient difference is scale. Moving from ~1.5B to ~175B parameters affects the learned function capacity, enabling emergent behaviors: more robust in-context learning (few-shot), better multi-step reasoning heuristics, and longer coherent generation. Scale increases model expressivity and the ability to memorize and generalize patterns from a web-scale corpus. However, scale also magnifies cost, memory footprint, and inference latency; it also increases the engineering burden if you attempt to host large weights yourself.
Training Data & Tokenization
GPT-3 received training on a tremendously larger, more diverse web-scale collection than GPT-2. This expanded data assortment boosts versatility but likewise amplifies susceptibility to flawed tags, distortions, and factual mistakes. Encoding methods and data preparation flows advanced to manage uncommon tokens and cross-language data more effectively at volume, granting GPT-3 an edge on diverse inputs.
Few-shot Learning: Why GPT-3 shines
GPT-3 proved that pure model magnitude yields strong zero-shot proficiency: supplying a few samples in the input triggers instant task adjustment without parameter tweaks. This diminishes the demand for intensive customization across numerous jobs, speeding up development cycles.
Real-world behavior: coherence, reasoning, and failure modes
- Smoothness / Consistency: GPT-3 usually generates extended, more logical texts.
- Multi-stage logic: GPT-3 displays superior step-by-step-like performance right away, although still prone to mistakes.
- Flexibility: GPT-2 gains hugely from field-specific adjustment; GPT-3 gains further from input crafting and zero-shot samples.
- Fabrications & accuracy: Both systems invent facts; GPT-3 cuts certain flaws, but doesn’t end invention. Employ RAG + checkers for critical details.
The Shortcut Comparison: GPT-2 or GPT-3?
| Dimension | GPT-2 (1.5B) | GPT-3 (≈175B) |
| Release | 2019 | 2020 |
| Parameters | ~1.5B | ~175B |
| Weights | Open/downloadable | Historically API-only (flagship) |
| Hosting | Self-host / on-prem | Managed API (historically) |
| Few-shot | Limited | Strong |
| Fine-tuning | Easy and cheap | Historically less common, instruction-tuning is often used |
| Best for | On-device, offline, high-volume narrow use | General-purpose assistants, few-shot tasks |
| Known failure modes | Lower baseline fluency | Hallucinations, cost & latency |
AI Pitfalls Exposed: Weaknesses and How to Overcome Them
Hallucinations
- Problem: Models invent facts or assert unsupported claims.
- Mitigation: Retrieval-augmented generation (RAG), citation-aware outputs, post-generation verifiers, or grounding with a database. For high-stakes output, require an evidence field and mark sections flagged by verifiers.
Bias & toxicity
- Problem: Both models reflect biases and toxicity in training corpora.
- Mitigation: Safety filters, metadata-aware prompting, red-team testing, and moderation layers. Use classifier-based screens and human-in-loop review for sensitive outputs.
Latency & cost
- Problem: Large models cost more per token and have higher latency.
- Mitigation: Distill or quantize models, use ONNX/Triton inference stacks, batch requests, cache outputs, and route cheap queries to smaller tuned models.
Price vs Power: The True Cost of GPT-2 & GPT-3
Self-host (GPT-2 and open small models)
Pros
- Lower long-run marginal cost after infra amortization.
- Full control over data and privacy.
- Offline operation is possible.
Cons
- Significant upfront GPU/infra capital expense.
- Ops complexity for scaling, monitoring, and reliability.
- Less convenience for bursty traffic.
Managed API (GPT-3)
Pros
- No hosting ops for model serving.
- Built-in autoscaling and provider SLAs.
- Safety tooling and monitoring are often included.
Cons
- Per-token cost scales with usage.
- Latency depends on the network and provider.
- Data-sharing policies require privacy review.
Rule of thumb: Self-hosting wins economically at stable, very high QPS for narrow tasks. For early prototypes or variable traffic, APIs minimize time-to-market.
The Real Price Tag: GPT-2 vs GPT-3 TCO Simplified
API path calculations
- Estimate average tokens per request (input + output).
- Multiply by expected daily requests = tokens/day.
- tokens/day × provider per-token price = monthly API cost.
- Add error margins (10–20%) for bursts and retries.
Self-Host Path
- Hardware cost (GPU nodes) + networking + storage.
- Electricity and datacenter fees.
- SRE/DevOps labor for reliability and updates.
- Amortize hardware across 2–3 years.
- Add contingency for model retraining or refresh.
Decision heuristic: If monthly API cost > monthly amortized hardware + ops + electricity by a comfortable margin for expected traffic, consider self-hosting; otherwise, prefer API.
When Cheap and Fast Beats Big: Choosing GPT-2
- You require offline or air-gapped operation.
- Regulatory compliance requires on-prem processing.
- Extreme query volumes where the marginal per-request cost must be minimal.
- Heavy domain-specific fine-tuning is planned.
Examples: embedded vehicle assistants, internal document summarizers, or a high-volume narrow-API for known transformations.
When to choose GPT-3
- You want strong few-shot performance with minimal fine-tuning.
- Your team prefers managed infrastructure and out-of-the-box safety features.
- Rapid prototypes and varied tasks dominate the roadmap.
Examples: customer-facing chatbots, multi-function writing assistants, or startups that must iterate fast without managing GPU fleets.
Hack GPT-3 Power Without the Price Tag
- Instruction-tune a smaller model (FLAN-style). Fine-tuning on instruction datasets yields big gains vs vanilla models and is cost-efficient.
- Hybrid routing. Use small tuned models for routine queries; escalate complex queries to GPT-3.
- Retrieval augmentation (RAG). Attach a vector store + retriever to ground outputs and reduce hallucinations.
- Prompt templates & structured outputs. Force JSON or fixed schemas to simplify parsing.
- Caching & deduplication. Cache repeated queries and responses; dedupe near-identical prompts before inference.
Instruction-tuning, Engineering, and the FLAN Lesson
Instruction-tuning means fine-tuning a model on datasets where tasks are expressed as natural-language instructions. The FLAN family showed instruction-tuned smaller models often match or exceed untuned larger models on many zero-shot tasks. For product teams, the FLAN approach is high-value: spend engineering cycles building a robust instruction-tuning pipeline, and you can get many GPT-3-like behaviors at far lower inference cost.
Practical steps to instruction-tune:
Collect high-quality instruction/response pairs across tasks.
- Mix in a few-shot exemplars during training for in-context behavior.
- Evaluate on a held-out instruction set and tune temperature/sampling.
- Deploy with a lightweight safety-filtering layer.
Upgrade Path: Moving from GPT-2 to GPT-3 Made Simple
- Inventory prompts: Collect 100–500 representative prompts and inputs from production.
- Build a test harness: Standardize inputs, expected outputs, scoring rubric, and logging of tokens/latency.
- Run A/B tests: Compare tuned GPT-2 vs GPT-3 across the inventory. Record quality, hallucination rates, latency, and tokens.
- Estimate incremental cost: tokens × daily calls × provider per-token price; add overhead for longer outputs.
- Uptime & speed check: Align API response time to app guarantees or include async paths/caching.
- Data safety & rules: Verify data handling rules for the API and legal duties.
- Backup/checker: Use a search tool or small model as a fact-checker for key results.
- Speed tweaks: Refine inputs; think about prompt-training compact models.
- Launch steps: Test group → gradual release → track stats and user input.
Experiment Table: GPT-2 vs GPT-3 Prompt Results
| Prompt | What to measure | Why it matters |
| “Translate this paragraph to plain English.” | Accuracy, length, Hallucination | Summarization quality |
| “Generate 5 subject lines for email about product X.” | Creativity, relevance | Marketing utility |
| “Extract named entities in JSON.” | Structure correctness | Integration readiness |
Run each prompt A/B with:
- GPT-2 (fine-tuned) with beam or sampling settings
- GPT-3 (few-shot) with different temperature values
Track pass/fail and manual quality scores.
Quick Build: GPT-2 to GPT-3 Implementation Guide
- Decide hosting model (self-host vs API).
- Build tests (100 representative prompts).
- Run A/B and collect metrics (quality, latency, cost).
- Decide instruction-tuning cadence.
- Add RAG, verifiers, and safety filters.
- Monitor production usage and iterate.
Cost calculator
- Avg tokens/request = input_tokens + output_tokens
- Daily requests = R
- Monthly tokens = Avg tokens/request × R × 30
- API monthly cost = Monthly tokens × $/token (provider rate)
- Self-host monthly cost = (Hardware amortization + electricity + ops labor) / 12
Under-the-Hood: Small-Model Engineering Secrets
- Quantization & distillation: 4-bit/8-bit quantization and task-specific distillation reduce inference cost significantly while retaining much of the behavior you need.
- Batching & caching: Batch small requests and cache deterministic outputs, especially for template-driven prompts.
- Model verifiers: Run a fast, smaller verifier model to cross-check facts or detect unsafe content before returning outputs to users.
FAQs
A: No. GPT-3 is stronger for many open-ended tasks due to its scale and few-shot learning, but a well-tuned GPT-2 (or an instruction-tuned small model) can outperform GPT-3 on narrow, domain-specific tasks and will be cheaper at scale.
A: The original 175B GPT-3 weights were not publicly released; historically, access has been via API. Running a model of that size locally needs huge infrastructure. Many open-source large and distilled models are available as competitive alternatives.
A: Instruction-tuning means fine-tuning on many tasks written as natural-language instructions. It makes models better at following user requests and can make smaller models compete with larger ones. It’s recommended that you control the training path.
A: Multiply average tokens per request (input + output) by expected daily calls and the provider’s per-token price. Check the provider’s pricing page for the latest numbers.
Conclusion
No outright victor exists between GPT-2 and GPT-3—the ideal selection hinges on your limitations. GPT-2 suits squads demanding local deployment, minimal extra expenses at volume, and intensive field customization. GPT-3 shines as the top ready-to-use option for zero-shot jobs, extended-text consistency, and groups favoring managed platforms. In 2026, peak-performing live systems often employ blended setups: customized compact models for routine volume, ensemble big-model queries for premium needs, and RAG/prompt-refinement to boost accuracy and curb fabrication. Consistently verify via a benchmark evaluation kit, track tokens and response time under real-world pressure, and explore directive-finetuning as a budget-friendly route to superior performance—FLAN-like adjustment typically yields the biggest return on your processing investment. Set to proceed? Kick off with a 100-example A/B comparison and a transition roadmap—if desired, I can create the complete evaluation