
Introduction
This is a practical,-oriented, developer-focused, long-form guide for engineering teams, ML engineers, and platform owners who are evaluating, integrating, or migrating workloads to Gemini-2.5-pro. It explains why the exact model id string matters, how to design token-aware systems, recommended production practices, reproducible benchmarking recipes, and a deployable migration checklist that you can paste into a repo or runbook.
Unlocking Gemini-2.5-Pro: Google’s AI Titan
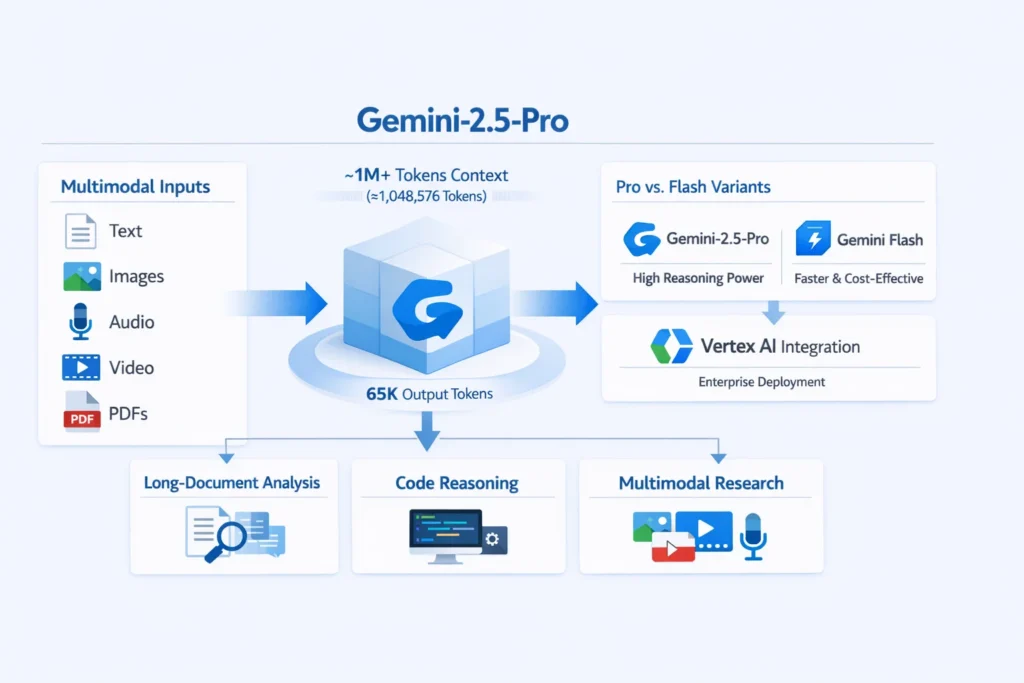
Gemini-2.5-pro is a high-reasoning, multimodal family member in Google’s Gemini 2.5 line. In/ML terms: it is a large-scale transformer-based reasoning model optimized for multi-modal token encodings (text + vision + audio/file embeddings) and architected to handle extremely long sequence contexts (on the order of ~1,048,576 tokens). It is intended for tasks that require deep chain-of-thought style reasoning, complex codebase understanding, multi-document summarization, and workflows that combine text, images, and file artifacts. Use it when you need model capacity and context length that exceed what shorter-window “flash” models provide.
Gemini-2.5-Pro: Exact Model IDs and Versions You Must Know
In production code and infrastructure-as-code (IaC), the string you pass to the API is the contract between your service and the model. Typos break provisioning, CI, and infra audits. The canonical, exact model identifier string you should use is:
Gemini-2.5-pro
- gemini-2.5-pro — canonical Pro model (this guide targets this id).
- gemini-2.5-pro-preview-* — preview or experimental builds; treat these as unstable.
- gemini-2.5-flash / gemini-2.5-flash-lite — cost/latency-optimized versions for high-throughput short-turn tasks.
- gemini-2.5-* — other sibling variants for specific latency/throughput trade-offs.
What Makes Gemini-2.5-Pro Tick: Features and Limits
- Supported modalities: Text, images, audio, video, PDFs/file contexts; treat each modality as token sequences or linked file references for large inputs.
- Max input tokens (context window): ~1,048,576 tokens (≈ 1.05M). This is the defining capability — it allows you to send ultra-lengthy contexts without external chunking.
- Max output tokens (typical): Up to ~65,536 tokens for generated outputs (varies by endpoint/config).
- Rate limits & quotas: Per-region, per-project quotas and rate limits apply — confirm in the Vertex console. Quotas include tokens-per-minute, requests-per-minute, and daily token budget caps.
Why Gemini-2.5-Pro’s Token Budget Changes Everything
- You can represent entire document collections, long codebases, or multi-file corpora as a single context and ask the model to do global reasoning (search, summarization, refactor suggestions).
- However, larger contexts mean bigger I/O, longer compute time, and higher token costs. Think in terms of token economics: not every request needs the whole 1M tokens. Use the Pro model where global context is truly necessary; use flash variants for short-turn interactions.
Gemini-2.5-Pro’s Thinking Engine: What Powers Its Decisions
Modern generative systems often expose internal reasoning modes or hyperparameters that bias the model toward deeper multi-step reasoning (sometimes marketed as “deep think” or “enhanced reasoning”). From an NLP perspective, those modes change the internal attention dynamics and may favor multi-step latent computations, which often means higher latency and cost but improved performance on multi-hop reasoning tasks. Benchmark those modes for your tasks; don’t assume one setting is universally best.
Rate Limits & Batch Tokens
- Rate limits are often region- and plan-dependent. Enterprise Vertex quotas differ from public tiers.
- Proof-per-day and batch-enqueued token quotas may be large for firm plans; verify during procurement.
- Design your client to detect 429 and 503 and apply random backoff with jitter.
Alive & Chunked Uploads Pattern
- Upload large binaries or long documents to cloud storage (GCS).
- Pass references (URIs or file IDs) to the model rather than raw content.
- Request streaming outputs so you can process partial tokens early and reduce client memory usage.
Error Rate-Limit Handling
- Retry on HTTP 429 / 503 with exponential backoff and randomized jitter.
- Log request metadata: Model id, token-count estimate, payload size, user/session id.
- Implement circuit breakers and fallback to cheaper model variants for non-critical tasks.
Production-Ready Gemini-2.5-Pro: Your Ultimate Migration Guide
This checklist is designed to be copied/pasted into runbooks or repo READMEs and executed before switching production traffic.
Pre-Launch
- Inventory workloads: Label flows that require >64K tokens or multimodal inputs; categorize by RISK and COST (High / Medium / Low).
- Model mapping layer: Add a config mapping friendly names to model id strings to avoid typos.
- Cost simulation: Sample 100 representative calls, measure tokens, latency, and cost-per-call.
- Security & compliance: For sensitive inputs, implement redaction and PII filters before sending data into models.
- Test harness: Create reproducible prompts (20–50) for automated benchmarking and human evaluation.
Canary plan
- Sandbox tests: Run unit + integration tests with representative large contexts.
- Canary: Route 1–5% traffic for 48–72 hours, monitor for latency, error spikes, and hallucination frequency.
- Ramp: 25% → 50% → 100% with automated health gates.
Implementation Checklist
- Add model mapping in config (example above).
- Client-side token accounting & monitoring (estimate tokens for prompt + expected answer).
- Chunked ingestion & progressive summarization for extremely large file sets: break into chunks, summarize each, then combine.
- Unit tests + end-to-end tests with human annotations for safety-critical flows.
- Retries and circuit breakers around network failures and rate-limit responses.
- Cache repeated responses to reduce repeated token spend.
Monitoring & observability
- Token usage per call (prompt + expected answer).
- Error rates (5xx, 4xx) and their breakdown.
- Latency percentiles (p50, p95, p99) by context size.
- Top prompts with the highest token usage.
- Cost by pipeline (which burns most tokens).
Cost Saving Patterns
- Prefer summary pipelines: chunk → summarize chunks → combine summaries (instead of sending 1M tokens for every request).
- Reserve gemini-2.5-pro for heavy reasoning; route high-volume short-turn tasks to gemini-2.5-flash.
- Cache and reuse model outputs where semantics permit.
What the Model Card Reveals About Gemini-2.5-Pro
Why Read the Model Card
Model cards distill benchmark results, known failure modes, and risk mitigations. Convert the model card into a one-page compliance checklist for product and legal teams.
Practical checklist
- Note tested benchmark scores in math, code, and reasoning suites.
- Record known limitations: hallucination tendencies, Demographic biases, and domain-specific failure cases.
- Map mitigation: guardrails, prompt engineering templates, automated filtering, and human review pipelines.
How to Benchmark
- 5 small prompts (≤1K tokens)
- 5 medium prompts (1K–64K tokens)
- 5 large prompts (64K–500K tokens)
- 5 ultra-large prompts (~1M tokens)
Measure:
- Throughput (requests/sec), mean latency, median latency, and 95th percentile latency.
- Task correctness via automated scoring + human evaluation.
- Token consumption per request.
Tip: Publish raw prompts, scoring scripts, and result artifacts in a public repo to increase trust and backlinks.
How to Maximize Gemini-2.5-Pro with Vertex AI
Availability & Enterprise Features
Gemini-2.5-pro is integrated with Vertex AI. Vertex provides:
- Quotas and regional deployment controls.
- IAM and logging integration with Cloud Audit Logs.
- Network controls (VPC-SC) and private access patterns.
Billing & Quotas
- Estimate cost per million tokens and create budget alerts in GCP billing.
- Set quota alerts and programmatic checks early; quotas vary by model and region.
Security & Networking Tips
- Use VPC-SC for private Vertex-to-GCS interactions.
- Apply least-privilege IAM to service accounts that call the model.
- Log request IDs and token counts to Cloud Logging for traceability.
Cost-Saving Architecture Patterns
- Cache frequent responses for repeated prompts.
- Use summarization pipeline: chunk → summarize each chunk → combine summaries.
- Route low-latency, short-turn tasks to flash variants.
Gemini-2.5‑Pro vs the Competition: Who Wins?
| Feature / Metric | gemini-2.5-pro | Typical competitor (GPT-family, etc.) | Notes |
| Model id | Gemini-2.5-pro | vendor-specific strings | Use exact id strings in API calls. |
| Max input tokens | ~1,048,576 | varies (some vendors preview 2M) | Gemini’s large context window is a primary advantage. |
| Max output tokens | up to ~65,536 | varies | Good for long artifact generation. |
| Multimodal | text/images / audio/video / PDF | many vendors support multimodal, differences remain | Differences in grounding & tool support—read model card. |
| Enterprise platform | Vertex AI | vendor cloud equivalents | Vertex integrates with the GCP ecosystem. |
| Best use cases | long-doc analysis, code reasoning, multimodal research | short chat/low-latency tasks | Choose by latency/cost tradeoffs. |
Content & Backlink Strategy
- Publish a reproducible benchmark repo on GitHub with raw prompts and a scoring script.
- Offer downloadable assets: migration checklist PDF, developer quickstart 1-pager.
- Run a tutorial webinar and post the replay for link-building.
- Outreach: developer blogs, forums, and cloud user groups.
FAQs
A1: Use gemini-2.5-pro exactly (lowercase, hyphens). Confirm the model id in the official models list or the Vertex console before production.
A2: Input up to ~1,048,576 tokens and output up to ~65,536 tokens (typical). Always verify official docs for your region/model release.
A3: Yes — the Pro variant supports text, images, audio, video, and PDFs via Vertex/Generative API. Use cloud storage references for large files.
A4: No — reserve Pro for heavy reasoning and large-context jobs. For high-volume short requests, use flash variants to save latency and cost.
A5: Google’s model cards and technical blog posts contain safety evaluations, failure modes, and mitigation guidance. Convert key points into product-level checklists.
Final verdict
Gemini-2.5-pro is a strategic tool for teams needing very large context windows and advanced reasoning. Operational success depends on careful token management, chunking or summarization pipelines, observability, and Vertex-based enterprise controls. Reserve Pro for the heavy-lift scenarios; use flash variants for high-volume, low-latency work. Publish reproducible benchmarks and a clear migration checklist to increase credibility.