
Introduction
GPT-4 (Vision / multimodal) — commonly abbreviated GPT-4 Vision-4V — is a multimodal transformer family that fuses high-capacity language modeling with learned visual representations so that textual context and pixel-derived embeddings can be jointly reasoned over. From an NLP practitioner’s perspective, GPT-4V converts images to dense vector tokens, aligns those vectors with textual tokens via cross-attention layers, and performs autoregressive or encoder-decoder style decoding to emit structured text, JSON, or labels. That architecture enables product features that look deceptively simple: GPT-4 Vision high-quality alt-text, visual question answering, SKU matching, and table extraction — but under the hood, these are cross-modal retrieval, conditional generation, and structured-output tasks requiring careful prompt engineering, calibration, and evaluation.
GPT-4 Vision: This guide targets product managers, ML engineers, applied NLP researchers, and growth leaders who want a defensible, production-oriented playbook for launching multimodal features. You’ll get: an NLP-style explainer of internals, prompt templates and A/B variants, a robust evaluation checklist focused on hallucination and calibration, test-set and labeling specs, an enterprise pilot roadmap, and a performance dashboard template you can drop into your monitoring stack.
Quick verdict — Should your Team Adopt GPT-4 Vision now?
Adopt now if your product depends on visual understanding integrated with language (visual search, catalog mapping, dynamic alt-text that improves accessibility metrics), and you can run a controlled pilot with human validators and deterministic verification. Adopt when you have a measurable business metric (conversion or time-saved) and the means to label a representative dataset.
Pilot now if you want to measure ROI—e.g., conversion lift from image-based product search—using bounded datasets, a deterministic validator layer (SKU DB lookups, image-similarity scores), and an explicit human-in-the-loop route for low-confidence outputs.
Wait or limit if your use case is safety-critical (medical diagnosis, forensic evidence, autonomous control). Those applications require clinical or domain-specific validation, regulatory review, and institution-level governance before production rollout.
GPT-4 Vision: How AI Sees, Understands, and Reasons
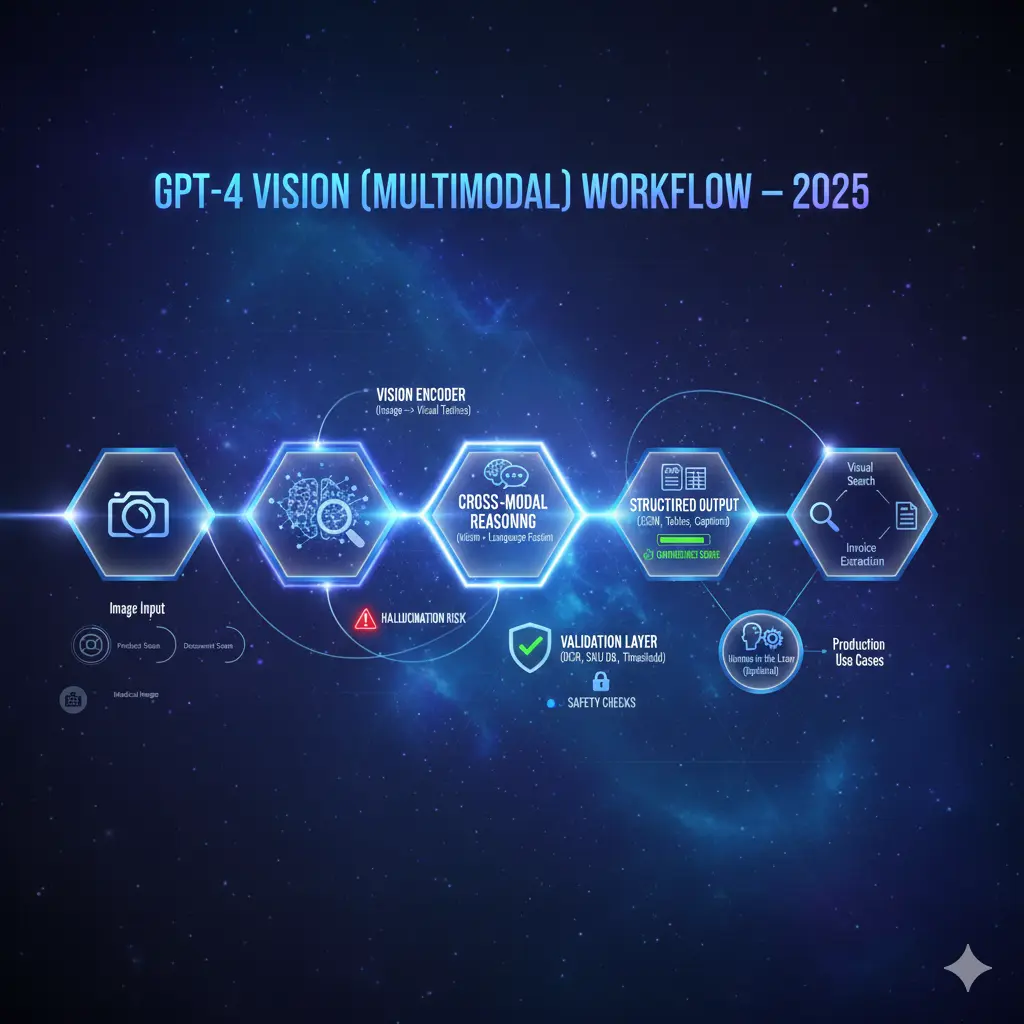
From an NLP engineering lens, GPT-4V is a cross-modal transformer that ingests two modalities and produces language-conditioned outputs.
- Image → Dense Tokens (Vision Encoder)
An image is passed through a learned vision encoder (similar in spirit to ViT/PatchEmbed or a convolutional backbone) that maps patches/regions to dense vectors. Think of these vectors as “visual tokens” analogous to word embeddings. The encoder may also produce positional encodings for spatial structure. - Text Tokenization & Embeddings
The textual prompt is tokenized and converted to embeddings using the same or a compatible token embedding space. For multimodal coherence, the model learns projection matrices so image vectors and text embeddings can be jointly attended. - Cross-attention / Fusion Layers
Core to multimodal reasoning is fusion: cross-attention layers allow text tokens to query visual tokens (and vice versa in some architectures). This lets the model ground lexical items in pixels and perform aligned reasoning (e.g., “what color is the shirt?” -> attend to the region representing clothing). - Conditioned Decoding / Output Heads
After fusion, the model decodes to produce textual outputs. When structured output is required (JSON, CSV), the prompt and system instructions constrain the decoder so it emits valid, parseable tokens. Some systems provide special output heads for classification or structured extraction to increase reliability. - Confidence & Calibration Signals
Modern deployments augment the model with calibrated confidence estimates (either internal token logits converted to confidence measures or external verifier modules). These are critical for human handoff logic. - Pipelines, Not Oracles
Practically, GPT-4V is a component in a pipeline: image pre-processing and OCR, deterministic validators (database lookups, image-similarity), and human queues are required to make outputs production-grade.
GPT-4 Vision Key Technical caveats
Quality of input images. Low-descition, short objects, extreme occlusion, or motion blur lead to degraded embeddings and higher error rates. The model’s receptive field and encoder resolution determine sensitivity to small visual features (tiny labels, serial numbers).
Hallucinations. A core NLP-style failure mode is confident generation of unsupported facts (textual hallucination) or false-positive object claims. Hallucinations manifest when the decoder overgeneralizes from partial cues or when cross-modal attention spreads incorrectly.
Domain shift. General pretrained models are trained on broad internet imagery. Specialized domains (medical scans, manufacturing x-rays) require domain adaptation, either by fine-tuning or by building strong deterministic checks.
Calibration & confidence misuse. Raw model logits are not well-calibrated as probabilities. Convert model scores through temperature scaling, isotonic regression, or use a verification model trained to predict human agreement.
Privacy & PII risk. Images often contain personally identifiable information (faces, license plates, documents). Treat visual inputs as sensitive—apply redaction, consent flows, and retention rules.
Latency & cost. High-resolution images and large context windows increase compute costs. Design tiered pipelines where lightweight filters handle obvious cases and the multimodal model handles edge cases.
GPT-4 VisionTop Real-World Use Cases
E-Commerce & Visual Search
Problem. Users upload photos expecting to find the right SKU or similar items.
NLP-style solution. Convert image to attributes (category, color, visible brand logos) and normalized tokens (taxonomy IDs). Use the produced attributes as structured queries for a deterministic SKU matcher or as queries in a vector search index.
Metrics to measure. precision@3, recall for relevant SKUs, conversion delta (A/B), return rate reduction, human-handoff rate.
Recommended guardrails. Always pair LLM outputs with deterministic validators: exact OCR matching for textual labels, image-similarity thresholds, and SKU DB lookups. If match_score < threshold, route to human review or return a conservative result list.
ROI example. If image search increases top-3 relevance and reduces friction for mobile users, you can see conversion uplifts in the +5–10% range in pilot traffic; measure cost per conversion via model-inference + human-review math.
Accessibility & Education
Use case. Auto-generate alt-text and concise scene descriptions.
NLP approach. Treat alt-text generation as controlled generation with strict length and safety constraints. Use template-based decoding (e.g., “Return only a single-sentence description, no advice or medical claims.”) and enforce forbidden token lists.
Implementation notes. Keep descriptions short, factual, and avoid inference beyond the image content. Human edit passes for critical content are recommended.
Healthcare
Use case. Assist clinicians with image summarization or triage.
NLP cautions. Models may suggest plausible but incorrect diagnoses. Use GPT-4V only as an augmenting summarizer or secondary opinion; never as an autonomous diagnostic system. Require clinical validation, dataset-level bias checks, and institutional sign-off.
Manufacturing & Defect Detection
Use case. Detect surface defects and produce inspection reports.
Hybrid approach. Combine classical CV defect detectors (thresholding, morphological filters) with LLM for interpretive reporting. LLMs can translate raw detections into human-readable explanations and remediation steps.
Document Tngestion
Use case. Extract invoice fields and tabular data from photos.
Pipeline approach. Preprocess with OCR (Tesseract or commercial services) to get text tokens; feed OCR text plus the image context into the LLM for structural extraction and normalization. LLMs excel at normalizing dates, currencies, and entity linking.
Safety, Hallucinations & an Evaluation Checklist
What to Measure
- Accuracy for classification/label tasks (per-class F1).
- Precision/Recall for detection tasks.
- Hallucination rate: % of Outputs containing unsupported claims.
- Human agreement rate: % Agreement between model output and human labelers.
- Latency & cost per image.
- False-positive business cost: Real-world financial impact.
Mitigation patterns
- Human-in-the-loop: Route low-confidence or high-stakes outputs to human validators.
- Deterministic validators: OCR, DB lookups, image-similarity thresholds.
- Confidence thresholds: Block or degrade output below calibrated cutoffs.
- Reject pathways: Instruct the model to return “no confident answer” instead of guessing.
- Adversarial testing: Run occlusion/low-light/rotated images to find brittle failure modes.
- Sampling & logging: Persistent logs for prompt, model version, and returned tokens for audits.
Comparing vendors — Quick Buyer’s Checklist
When evaluating multimodal vendors, score them on concrete axes rather than marketing. Run blind tests on your domain dataset.
Essential axes
- Domain accuracy: Performance on your images and edge cases.
- Latency & throughput: Inference P95 latency, cost per 1k images.
- Structured output stability: How reliably the API returns valid JSON or schemas.
- Privacy & compliance: Data residency, retention, and enterprise SLAs.
- SDK & integration quality: Ease of error handling and retries.
- Safety transparency: System cards, red-teaming reports, and known limitations.
Run blind vendor tests using a private holdout and evaluate on the same labeling spec. Platforms that collect telemetry, such as Helicone, can help compare real-world latency and cost.
Implementation Roadmap & Cost Checklist
A pragmatic, step-by-step plan to move from pilot to production.
Define Success & Dataset
- Build a labeled test set that mirrors expected production traffic. Include base, edge, and adversarial cases.
- Decide metrics: precision@k, hallucination rate, conversion uplift, human-handoff rate, cost-per-success.
Labeled test set spec (short)
Aim: ~5,000 images minimum for stable signals. Suggested split:
- 3,000 base cases
- 1,000 edge cases (low light, occlusion)
- 1,000 adversarial/negative examples
For each image, include: ground-truth labels, bounding boxes (if relevant), SKU ids, and a short human note describing ambiguous cases.
Pilot
- Integrate API + validator layer (OCR, SKU DB lookups, image-similarity).
- Implement human review for outputs with low confidence or high cost.
- Run A/B: control vs. experiment on a traffic slice.
Safety & compliance
- PII detection and redaction.
- Consent banners and retention policy.
- Provenance logging: model version, prompt, tokens, and validator results.
Scale & Monitor
- Drift detection: monitor input distribution shifts.
- Latency optimization: use caching and lighter models for hot flows.
- Cost controls: rate limits and budget alerts.
- Retrain & prompt-tune: use validated data to tune prompts or fine-tune small models.
Cost checklist
- Model inference cost per image.
- Human-review staffing cost per 1k images.
- Storage, logging, and analytics cost.
- Engineering integration and maintenance effort.
Hands-on Engineering Checklist
- Version prompts & outputs (git for prompt templates).
- Golden tests: Fixed inputs -> expected structured outputs for regression.
- Reject pathway: Ensure low-confidence outputs are rejected or routed to humans.
- Metric dashboard: Conversion uplift, hallucination rate, and latency P95.
- Privacy-first record keeping: Only retain what’s compliant.
- A/B test infrastructure: Enforce randomization, logging, and analysis plan.
Content Examples & Mini-Cases
Problem. 10% of mobile visitors upload photos; they expect matching SKUs.
Pilot. GPT-4V extracts attributes → SKU matcher validates → return top-3.
Result. Example pilot: 9 percentage-point increase in mobile conversion; returns reduced by 4% after SKU confirmation.
Tip. Measure both business outcomes and error costs.
Accessibility Tool
Problem. Blind users need richer alt-text.
Pilot. GPT-4V produces descriptions; editors review 1% in real time.
Result. Engagement with accessible content rose 22%; editors detected 0.5% risky instructions.
Pros & Cons GPT-4 Vision
Pros
- Unlocks visual search, richer alt-text, and structured extraction.
- Fast to prototype using APIs and prompt patterns.
- Supports structured output (JSON) for pipelines.
- Active research and safety docs exist.
Cons
- Hallucination risk — requires mitigation.
- Domain shift can reduce out-of-the-box performance.
- Cost and latency considerations for high throughput.
- Privacy/regulatory complexity when processing PII.
GPT-4 Vision Table — Sample Pilot Metrics
| Metric | Pilot Goal | Measurement method |
| Precision @ top-3 | ≥ 0.85 | Manual labeling on sample traffic |
| Hallucination rate | < 5% | Sampled outputs judged by humans |
| Conversion uplift | +5–10% | A/B test vs control |
| False positive cost | Business-defined | Financial model |
| Latency P95 | < 800ms | API + infra monitoring |
Monitoring & Observability
Log and dashboard metrics:
- Prompt, model version, and returned JSON.
- Hallucination rate, human-handoff rate.
- Latency P50/P95.
- Cost per successful match.
- Alerts on sudden spikes in low-confidence outputs or hallucinations.
Performance Dashboard Template
Essential panels:
- Conversion uplift (experiment vs control) — time series.
- Hallucination rate over time — time series with sampling.
- Human handoff rate & median review time — bar + gauge.
- Latency P50/P95 — histogram.
- Cost per successful match — table by day.
FAQs GPT-4 Vision
A: No, not as an autonomous diagnostic tool. Use for triage or research and requires clinical validation and clinician sign-off.
A: Yes — but for high-volume invoice processing, combine OCR libraries with LLM-based structure extraction and deterministic checks.
A: Use deterministic validators (DB lookups, OCR), confidence thresholds, human review, and adversarial testing. New research also proposes attention-guided steering to reduce hallucination rates.
A: There’s no universal winner. Run a blind domain-specific test to evaluate accuracy, latency, and cost for your use case. Platforms that collect real-world telemetry can help you compare.
A: Aim for ~5,000 labeled images with a mix of base, edge, and adversarial cases to get a stable signal.
Conclusion GPT-4 Vision
GPT-4V-like multimodal models bring NLP practitioners a powerful new substrate for product innovation: visual search, accessibility, structured extraction, and human-like description synthesis. But moving from prototype to production requires NLP discipline — schema-first prompt engineering, calibrated confidence signals, deterministic validators, domain-aligned evaluation datasets, and human-in-the-loop governance. Start with a 6–8 week pilot: collect a 5k labeled test set, build deterministic validators (OCR, DB checks), run blind vendor comparisons, and run an A/B experiment that measures conversion uplift and hallucination rate. Instrument drift detection, cost controls, and provenance logging. If pilot KPIs meet your pre-defined thresholds, scale iteratively while maintaining safety guardrails and continuous monitoring. If not, iterate on prompt templates, validator thresholds, and dataset augmentation before retrying. Done well, multimodal NLP systems can deliver meaningful product ROI while staying auditable and safe.