
Introduction
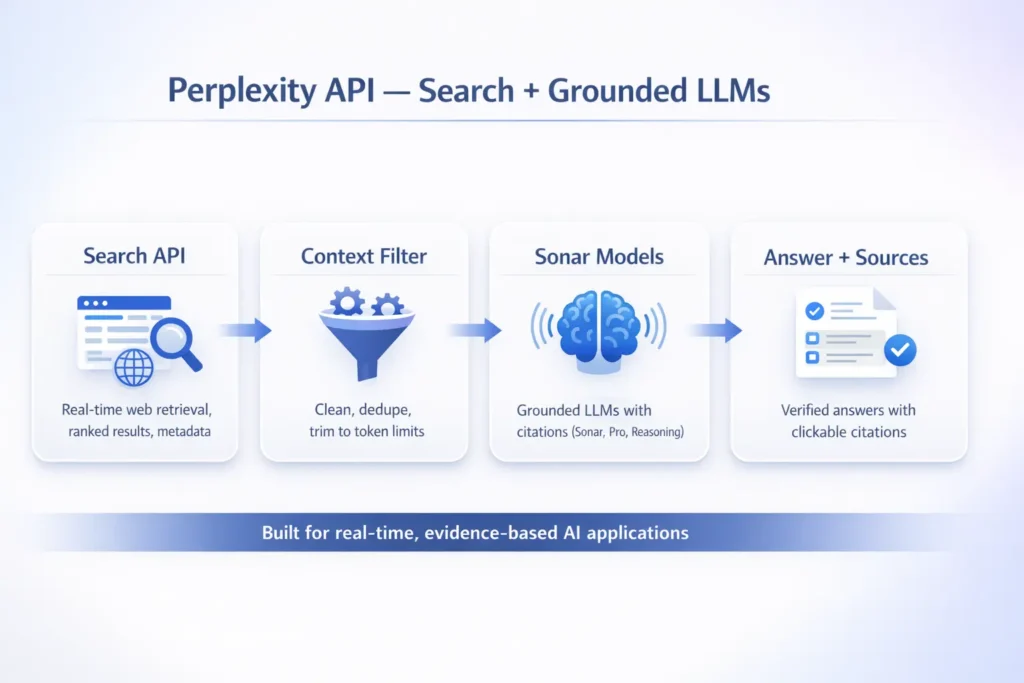
Perplexity API is an evidence-first answer engine that pairs a structured Search endpoint with grounded language models (the Sonar family) to return up-to-date, source-attributed answers. In terms, it’s a retrieval-augmented generation (RAG) platform: a retriever (Search) supplies candidate passages and metadata, and a grounded synthesizer (Sonar) conditions on that retrieved context to produce fluent, citation-aware responses. Use Perplexity when provenance, temporal freshness, and user-verifiable evidence are required — research assistants, knowledge bases, helpdesk agents, and dashboards that show links and publish dates. For bulk creative generation or very low-cost token-only workloads, token-centric providers may be cheaper. This guide covers conceptual NLP foundations (retrieval, reranking, grounding), practical integration flows (Search → context curation → Sonar), pricing patterns and estimation heuristics, production best practices (caching, truncation, monitoring), code examples evaluation metrics for grounding quality, assets for a pillar page, and a JSON-LD snippet — all written with an -first perspective and practical implementation advice.
What is The Perplexity API?
Perplexity API is best understood from a systems view as a retrieval-augmented generation stack with two cooperating components:
- Retriever (Search API) — Returns ranked passages/snippets, metadata (title, domain, publish date), and structured results that serve as evidence. From an NLP perspective, this is the candidate generation phase (lexical + neural retrieval), providing the context that constrains generation and reduces hallucination.
- Grounded LLMs (Sonar family) — Conditional language models that take retrieved context as external knowledge and synthesize answers while explicitly citing the provenance. In RAG terminology, this is the generator stage, except that it’s engineered to produce citation-rich outputs (structured attributes: source title, URL, publish date, excerpt offsets) rather than unconstrained tokens.
- Provenance: Each assertion can be traced to a snippet and URL, enabling human verification and compliance.
- Freshness: A continuously refreshed index (Search) allows answers to reflect recent web content without needing fine-tuning.
- Reduced hallucination: Grounding on retrieved context constrains the model to evidence it can cite, lowering unsupported claims.
Use it when your product’s correctness, auditability, or regulatory posture benefits from showing sources alongside generated prose.
Core Features & Models — What you Need To Know
Search API
- Purpose: Candidate passage retrieval (snippet text, title, URL, domain, publish date, ranking score).
- Application: The choice of the decision algorithm affects recall and precision. normal flows combine lexical search (BM25 or equivalent) for precision with dense retrieval (embeddings) for semantic recall, possibly followed by a neural reranker.
- Filtering & angle: Defined by domain, language, or region to reduce noise and tailor to governance needs.
Sonar Family
- Sonar (standard): Low-latency, cost-sensitive grounded model for typical Q&A synthesizing short answers from context.
- Sonar Pro: Higher-capacity grounding with improved reasoning, likely using larger context windows or model ensembles; better for multi-step synthesis and structured outputs.
- Sonar Reasoning: Tuned for chain-of-thought style reasoning and structured JSON outputs — useful when you need stepwise justification or machine-readable results.
SDK & OpenAI-compatibility
- SDKs for Python and Node/TypeScript are available, and compatibility with OpenAI-style chat completions can simplify migration if you already use those clients — usually by pointing the client at Perplexity’s base URL and using its API key.
When to choose Perplexity API — primary use cases
- Research tools & summarizers: Show where facts came from; useful for scholarly and journalistic contexts.
- Internal knowledge assistants: Compliance teams and legal desks need traceable answers and audit logs.
- Customer support & help desks: Reduce risk by attaching citations to product info, release notes, or policy pages.
- Dashboards & monitoring UIs: Embedding clickable sources lets users verify product specs or price changes.
- Chatbots that must be conservative and verifiable: Grounding improves trust; models can be tasked to only answer when evidence supports the claim.
Avoid Perplexity For:
- Cheap bulk creative copy where provenance is irrelevant.
- Use cases requiring heavy multimodal synthesis (images/audio) unless Sonar models support those modalities in your account.
Pricing — How Perplexity API charges
Note: precise prices change. Treat the following as illustrative heuristics and consult Perplexity’s official pricing page for current numbers.
- Search cost: Typically per-request (searches per 1k). Retrieval cost scales with frequency and query fanout.
- Grounded LLM cost: A mix of per-request fees plus token-style billing for input + output, especially when large context windows are used.
- Variant pricing: Sonar Pro / Sonar Reasoning costs more but improves grounding fidelity.
Example Bills Perplexity API
- Small app: 10k Search requests/month at a hypothetical $5/1k → ~$50 for Search only.
- Medium app: 100k Search requests/month → ~$500 + associated LLM token costs for any grounded calls.
- Research app: 50k Search + 10k grounded LLM calls → mixed per-request + token costs; offset by caching and context trimming.
Estimation Tips Perplexity API
- Measure average context size (tokens added from retrieved snippets) per query; This directly affects token costs.
- Profile output size (average tokens in generated answer).
- Estimate cache hit rate—Even a modest cache reduces retrieval and grounding cost dramatically.
- Use staging load tests to measure real token consumption under representative prompts and retrieval fanout.
Step-by-Step Integration patterns & Best Practices
- Search: Retrieve N top passages with metadata.
- Contextualize: Clean HTML, dedupe overlapping passages, trim to token budget using extractive summarizers or salient-sentence heuristics.
- Ground: Call Sonar model with an instruction template that forces citations, explicit answer length limits, and a required format (e.g., JSON with answer + sources).
Context Curation Techniques
- Extractive summarization: Compress retrieved passages to their salient sentences before passing to the model.
- Dedupe: Remove similar snippets using text-similarity thresholds to avoid repetition and preserve token budget.
- Chunk selection: Score passages by relevance, date, and domain trust, then pick the highest-value subset.
Caching
- Cache Search responses for short TTLs (30–300s) for freshness-sensitive apps.
- Cache LLM responses for identical queries with longer TTL when appropriate.
- Use stale-while-revalidate where UX demands immediate response, but you can refresh in the background (note: you must not claim asynchronous work later — implement server-side immediately).
Rate Limiting & Retries
- Implement exponential backoff with jitter for 429/5xx responses.
- Use SDK-provided retry wrappers when possible.
Cost Controls
- Cap context size and response length with hard limits in your backend.
- Enforce per-user quotas and rate limits to protect budgets.
- Instrument token consumption per request and alert on anomalies.
Observability
- Track requests, latency, token consumption, cache hit rate, and top queries.
- Monitor grounding metrics: citation precision (percentage of claims that have an actual supporting snippet), grounding recall (how often the system finds any relevant evidence), and hallucination rate.
Security & Governance
- Use a backend proxy to keep API keys secret and to enforce quotas.
- Implement content filtering and PII redaction before presenting any results.
Perplexity APIvs Alternatives
- Grounding quality: How accurately does the model cite and summarize supporting sources?
- Search control: Can you filter by domain or date? Can you retrieve metadata like publish date?
- Cost model: Per-request retrieval + tokenized grounded generation vs purely token-based models.
- Latency & scale: Throughput for combined retrieval + generation pipelines.
- Developer ergonomics: SDKs, streaming support, OpenAI-compatibility.
- Auditability & compliance: Exportable logs of citations, request traces, and provenance.
Decision tip: choose Perplexity when provenance and fresh web grounding are first-order requirements. If you need bulk, cost-effective generation or advanced multimodal outputs, consider evaluating other vendors.
Sample Architecture Perplexity API
- Backend proxy: Protects API keys, enforces per-user quotas, aggregates telemetry.
- Cache stage: Short-lived cache for Search results; separate cache for final LLM responses.
- Context filter: HTML cleaning, dedupe, extractive summarization, and token trimming.
- Grounded LLM: Sonar model synthesizes answer, attaches structured citations (title, URL, publish date, excerpt).
- Client: Displays tappable citations, domain trust signals, and a provenance panel for verification.
Troubleshooting & Common Pitfalls Perplexity API
Unexpected Cost Spikes
- Cause: Large contexts, long outputs, or heavy re-querying (low cache hit-rate).
- Fixes: Enforce token caps, apply stricter context trimming, introduce per-user rate limits, and alert on cost anomalies.
Stale Results
- Cause: Index refresh lag for very recent content.
- Fix: Combine the search index with targeted crawlers or publisher APIs for ultra-late-breaking content.
Hallucinations / Unsupported Assertions
- Cause: Insufficient or misleading context.
- Fix: Increase retrieval depth, strengthen the reranker, force citation requirements, or upgrade to Sonar Pro/Reasoning.
Low Recall for Niche Queries
- Cause: Limited index coverage or narrow retrieval heuristics.
- Fix: Augment retrieval with domain-specific connectors, internal DB integration, or knowledge graph augmentation.
Evaluation Metrics for Grounded Systems
- Answer relevance: Human-rated relevance scores or automatic proxies (ROUGE, BLEU are weaker for long answers).
- Citation precision: Fraction of model claims that have supporting citations.
- Grounding recall: Proportion of relevant external facts retrieved by the Search stage.
- Factuality/hallucination rate: Human-evaluated false claim frequency.
- Temporal accuracy: Whether claims refer to correct versions/dates (critical for time-sensitive queries).
- Latency & cost per query: Engineering KPIs to manage SLAs and budgets.
Design human evaluation tasks with clear annotation guidelines: label claims, verify each claim against provided sources, and mark missing or contradictory evidence.
FAQs Perplexity API
A: Perplexity typically offers free playground access and limited free usage, but API usage is billed for Search requests and token-based Grounded LLM calls — check the official pricing page for details.
A: Use Sonar (standard) for speed and cost sensitivity. Choose Sonar Pro or Sonar Reasoning for complex queries that need higher accuracy and structured reasoning.
A: Yes — surfacing citations improves trust and reduces hallucination risk, and is a key Perplexity advantage.
A: Yes — combine Search and Grounded LLMs to power chat that returns sourced answers. For freeform creative chat, evaluate cost tradeoffs.
Conclusion Perplexity API
Perplexity API stands out as a retrieval-augmented, evidence-first NLP platform built for applications where accuracy, freshness, and source transparency matter. By combining a powerful Search API with grounded Sonar language models, it enables developers to deliver verifiable, up-to-date answers instead of unsupported text generation. From an NLP perspective, Perplexity excels at controlled generation, reducing hallucinations through explicit context grounding and citation enforcement. If your product requires real-time web knowledge, auditability, and user trust, Perplexity API is a strong choice. For purely creative or low-cost bulk generation, alternative token-centric models may be more suitable. Used correctly, Perplexity API can form the backbone of reliable research tools, knowledge assistants, and evidence-driven AI experiences.