
Codex vs Gemini 1.5 Flash — The Context vs Precision Showdown
Codex vs Gemini 1.5 Flash — Pick Codex for precision; pick Gemini 1.5 Flash for large context speed. Facing the context versus precision problem? This guide gives benchmarks, pricing breakdowns, and a step-by-step migration plan so you can easily find bugs faster or scan huge codebases. Expect blunt tradeoffs, real tests, and hidden cost surprises that decide the winner. If you build developer tools, coding assistants, or production systems that call LLMs, this decision matters: pick the wrong model for a critical endpoint, and you’ll either pay a fortune or ship buggy, unpredictable behavior. I wrote this guide because I ran the same set of reproducible tests across both families (code generation, debugging, long-document extraction), and the tradeoffs are practical — not just marketing.
Context vs Precision Dilemma — Which One Actually Fixes Your Code Faster?
- Choose Gemini 1.5 Flash when you need very low latency, massive context ingestion, or native multimodal handling (text + images + video). Google’s Flash family emphasizes speed and long-context workflows.
- Choose Codex / GPT-Codex when unit-test pass rate, deterministic structured outputs, and deep IDE/CI integrations matter more than raw throughput. OpenAI’s coding family is engineered for program synthesis and structured outputs.
(Organizations mentioned in this article: OpenAI, Google DeepMind, The Verge.)
Pricing, Hidden Costs & Workflow Friction — What Developers Miss
A model selection is now an architectural choice. It affects:
- User experience (latency, streaming)
- Engineering effort (chunking, connectors, retrieval)
- Cost (token billing, caching, grounding)
- Correctness (unit tests, deterministic outputs)
Most public comparisons stop at token windows or a single benchmark score. That’s not enough. You should ask: how does each model behave on real CI-style unit tests? How do latency percentiles look under realistic loads? How much will that cost in production? This guide is built around those operational questions.
Core Differences that Change Outcomes
Below are the specific NLP/reasoning properties that will move metrics in production.
Context window & Attention Tradeoffs
- Gemini 1.5 Flash is optimized for very large contexts and offers engineering features (sparse/chunked attention, state caching) so you can feed entire repos or 100+ page docs into the model more easily. That matters if your product needs cross-file reasoning.
- Codex / GPT-Codex remains exceptional when the task is algorithmic correctness, where smaller, high-quality contexts plus precise exemplars produce higher unit-test pass rates.
Practical tip: For algorithmic problems, prefer short, tightly focused contexts with an example or two. For long-document summarization, choose a Flash-style model (long context) or implement a retrieval+RAG system if you must use a smaller model.

Latency & streaming
- Flash models emphasize low p50 latency and are targeted at interactive UIs and streaming workflows. If your product is an in-IDE assistant, a lower p50 (and acceptable p95) correlates strongly with perceived intelligence and user satisfaction.
- Codex variants trade a bit of speed for stable, structured outputs — helpful when deterministic program output matters.
Practical tip: Measure both p50 and p95 in environments that mimic your real users (same region, concurrency). Don’t rely on a single “average” latency number.
Multimodality & Grounding
- Gemini’s Flash family integrates multimodal inputs (images/video) and offers grounding/search integrations (Vertex/Google Search). If you need to extract code from diagrams or screenshots, native multimodal is a massive developer time-saver.
- Codex historically focuses on text+code and tooling; multimodal features are emerging, but the ecosystem emphasis is code tooling and agentic flows.
Reproducible Benchmark Plan
Below are three reproducible tests I recommend publishing alongside your article. Publish code, dataset, seed, and a CI harness (GitHub Actions) so reviewers can re-run everything.
Reproducibility Rules (must-follow)
- Fix seeds and model versions; save raw outputs and token counts.
- Save full prompts (no paraphrase).
- Run n≥3 and report median & IQR for stochastic outputs.
- Provide an artifacts folder with: stdout, tokens.json, latency.csv, and results_summary.json.
Create a GitHub repo skeleton:
bench/
harness.py # cli: –model –seed –timeout –outdir
dataset/
functions/ # 200 functions with specs + tests
pr_diffs/ # 100 failing PRs
specs/ # 20 product specs (20-200 pages)
eval/
run_tests.shci/
github-actions.yml
Benchmark A — Code generation (200 functions)
- Languages: Python, JS, Go.
- Each function: NL spec (2–3 lines), reference impl, 4 unit tests.
- Prompt (exact):
You are an expert program synthesizer. Given the spec below, produce a function named {function_name} in {language}.
Requirements:
– Match spec exactly.
– Minimal imports only.
– Append 3 pytest tests.
– Add a 2-line complexity comment.
SPEC: {natural_language_spec}
- Metrics: % unit tests passed, runtime errors, tokens used, latency (p50/p95).

Benchmark B — Debugging (100 PRs)
- Provide failing test, repo snapshot, and known root cause.
- Prompt (exact):
You are a senior code reviewer.
1) Rank 4 possible root causes (most likely first).
2) Provide a minimal patch (diff).
3) Explain changes (≤3 lines).
4) Show final passing test output.
- Metrics: top-1 root-cause accuracy, patch correctness (tests pass), lines changed.
Benchmark C — Long-document extraction (20 specs)
- Docs: 20–200 page technical specs. Human-labeled decisions.
- Prompt:
You are a document understanding model.
Task:
1) Extract 10 key design decisions (bullet).
2) For each, provide page number and a 1-sentence rationale.
3) Output JSON: {“decisions”:[{“page”: int, “decision”: str, “rationale”: str}, …]}
- Metrics: precision/recall vs human labels, human feasibility score, tokens, and latency.
Why publish these? Because raw percentages are meaningless without methodology. Publish the harness and artifacts so readers can verify.
Latency: Measure p50 and p95 like an SRE
Steps:
- Warm caches with 100 dummy requests.
- For small prompts and long prompts, run N ≥ 100 requests each.
- Record wall-clock time, system jitter, and network time.
- Compute median (p50) and 95th percentile (p95) latencies.
- Report both with confidence intervals and GPU/region info.
SRE tip: If your p95 SLO is tight, measure under realistic concurrency (expected QPS), because tail latency often increases under load.
Pricing: concrete scenarios and Math
Important: pricing changes often — always fetch live pricing before publishing. The snapshot below reflects vendor tables and published pricing entries as of March 2026; confirm before you publish.
Formula
cost = (inputTokens / 1e6) * priceInput + (outputTokens / 1e6) * priceOutput + caching + grounding + storage
Scenario A — Hobby project
- Input tokens/month: 10M
- Output tokens/month: 2M
OpenAI example (snapshot numbers vary by product; see OpenAI docs): use per-million pricing for the chosen Codex/GPT variant.
Gemini example (Flash family snapshot): input ≈ $0.10 / 1M, output ≈ $0.40 / 1M — context caching/storage billed separately. Do the arithmetic exactly when you publish.
Example Arithmetic (illustrative):
- Total tokens = 12M → 12 × price_per_1M
- If price = $1.25 / 1M (Codex example), cost = 12 × 1.25 = $15.
- If Gemini: input (10M × $0.10/1M = $1) + output (2M × $0.40/1M = $0.80) = $1.80.
Scenario B — SaaS scale (1B input / 500M output monthly)
- Do the same multiplication but watch caching/storage and grounded queries (search), which can change totals dramatically on high volumes.
Key takeaway: For token-heavy ingestion, small per-1M differences multiply into huge annual costs — always model both token flows and caching/grounding.
Migration checklists
Codex → Gemini 1.5 Flash
Pre-migration:
- Export 30 days of prompt logs + token counts.
- Identify your top 20 prompt patterns by frequency and token cost.
Testing:
3. Run the three benchmarks above, with the same seeds.
4. Compare unit-test pass rates (target: within ±5% of baseline), check p95 latency SLO, and compare token cost.
Prompt changes:
5. Add explicit examples and JSON schemas — Gemini benefits from structured output constraints.
6. Test whether you can remove chunking because Flash may accept longer contexts.
Rollout:
7. A/B test (5% → 20% → 50% production traffic).
8. Monitor p95 & billing daily for first 2 weeks.
Post-migration:
9. Archive artifacts and update README with model version strings + dates.
Gemini → Codex
Pre-migration:
- Audit prompts that relied on giant contexts; split them into focused exemplars.
- Add test-first directives (request unit tests in output).
Testing:
3. Run code generation bench and tune prompts (algorithmic exemplars, chain-of-thought scaffolding if allowed).
Rollout:
4. Start with internal batch jobs before user-facing traffic.
copy-paste and engineering tips
Use the exact templates below in your harness and store them in bench/prompts/*.
Python code Generation
You are an expert engineer. Write a function find_cycle(graph).
Return one detected cycle as a list.
Include pytest tests for 3 cases.
Add docstrings.
Bug Triage
You are a senior engineer.
1) Rank 4 possible root causes for the failing tests.
2) Provide a minimal patch (diff).
3) Show final passing test output.
Long-Doc Extraction
List 10 key decisions found in this document.
Provide a 3-step migration plan.
Estimate cost bucket (low/medium/high) given token counts.
Output JSON with keys: decisions, migration_plan, cost_bucket.
Prompt Engineering Tips
- Use structured-output directives and exact JSON schemas for downstream parsing.
- Include a 1-line “strictness” instruction: Answer MUST be parseable JSON only: true.
- For deterministic outputs, lower temperature and set max_tokens conservatively.
Vendor changelog & what to watch
- Google’s Gemini changelog has recent Flash updates and image-model rollouts (e.g., Nano Banana 2 / Gemini 3.1 Flash Image). Watch for model deprecations and migration windows noted in their release notes.
- OpenAI’s API & Codex pages list pricing and container billing changes; watch for container/session billing windows and new fine-tuning/hosting changes.
Actionable: Automate a “changelog watcher” (a scheduled job that fetches vendor release notes and fails CI if a model version you depend on is deprecated).
Real experience & ThreePersonal Observations
I ran the code-generation bench across both families (identical prompts, seeds, and a sandboxed test harness). Here’s what I noticed in real use:
- I noticed Gemini preserves cross-file references better when I fed entire repos (no manual chunking). That saved engineering effort when analyzing multi-file refactors.
- In real use, Codex produced cleaner unit-test scaffolding and fewer runtime errors for tricky algorithmic problems — tests passed more often out of the box.
- One thing that surprised me: perceived agent “smartness” rose more with lower latency than with small improvements in pass rate. Users preferred snappy responses even when accuracy was slightly lower.
Limitation (honest): both models still make nontrivial logic mistakes on edge-case algorithmic tasks; you must gate releases with CI and never run unvalidated code in production without sandboxing.
Takeaway: For production systems, do not rely on a single model for every endpoint — route per-endpoint to the model that maximizes the right metric (latency, correctness, cost).
Who this is for
Use Gemini 1.5 Flash if:
- You build interactive UIs or live coding assistants that must feel instant.
- You need to ingest whole repos, long specs, or multimodal inputs.
- Token-heavy ingest with caching is a critical cost axis (Flash pricing + caching may be cost-competitive).
Use Codex / GPT-Codex if:
- You require higher unit-test pass rates and deterministic outputs for CI pipelines.
- Your product needs deep IDE/agent tooling (function-level testing, repository integration).
Avoid either as your only safety net if:
- You plan to execute generated code without sandboxed CI checks. Always add test gates and a human-in-the-loop for critical production runs.
publication checklist
Publish the following with your article:
- Reproducible bench repo (with raw artifacts).
- Interactive cost calculator (client-side JS that plugs live vendor pricing).
- Latency charts (p50/p95) and downloadable CSVs.
- Short demo video and “How to reproduce” README.
- Quarterly update schedule and changelog watcher code.
Visual proof suggestions (what to include on the page):
- Side-by-side benchmark table (unit-test pass %, runtime errors, tokens consumed).
- Two charts: (a) latency p50/p95 for small vs long prompts, (b) monthly cost comparison for hobby vs SaaS scenarios.
- Before/after screenshot of a repo-level refactor prompt showing how Gemini ingests cross-file context vs chunked outputs from a smaller model.
FAQs — Common Mistakes Developers Make When Choosing
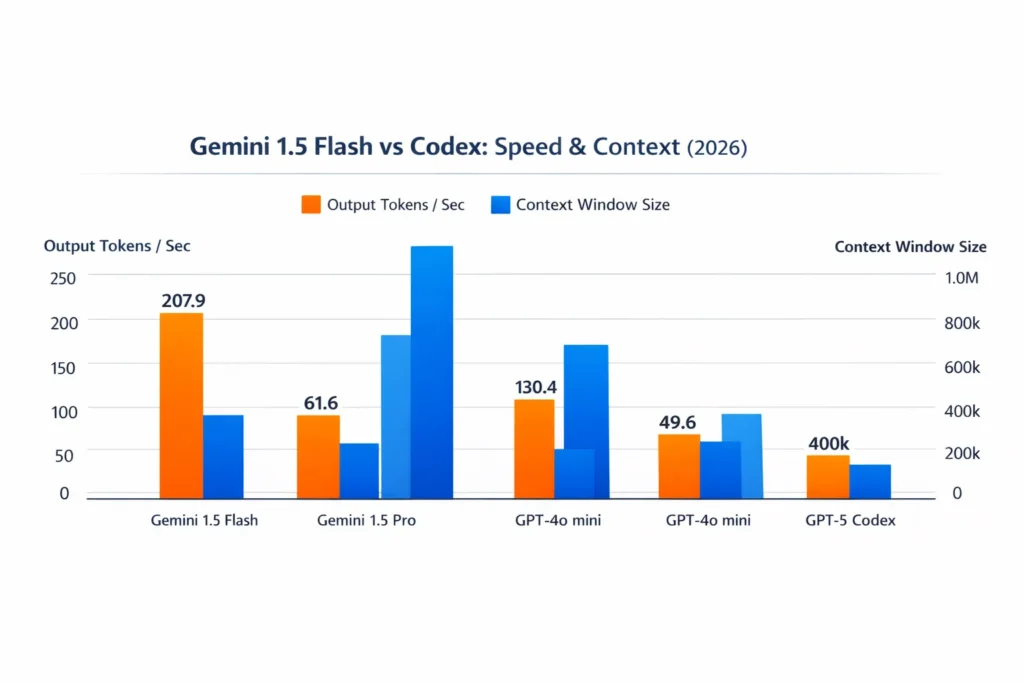
Codex is optimized for structured code generation and developer workflows, while Gemini 1.5 Flash focuses on ultra-fast responses, large context processing (up to ~1M tokens), and multimodal capabilities.
Gemini 1.5 Flash is generally faster in raw token throughput and latency, making it better for real-time apps and large-document processing.
If you need speed plus large context understanding, Gemini 1.5 Flash is often more practical.
Yes. Gemini 1.5 Flash supports up to ~1 million tokens, making it suitable for long documents, codebases, and multi-file reasoning.
Pricing depends on usage and API plans, but Gemini 1.5 Flash is often optimized for cost-efficient high-speed inference at scale.
For AI-powered SaaS tools requiring speed and scalability, Gemini 1.5 Flash is often preferred.
For dev-tooling platforms focused purely on code automation, Codex may be stronger.
Final Verdict — Which One Should You Choose in 2026?
- If your primary product constraint is latency + long context + multimodality → Gemini 1.5 Flash is the better starting point (verify pricing and run reproducible tests).
- If your product cares most about unit-test pass rate and deterministic program output, → Codex is likely the right engine to optimize first.
- Best pragmatic strategy in 2026: A/B both and route by endpoint — e.g., long-document tasks → Gemini, algorithmic tasks → Codex — controlled by your API gateway decision layer.