
GPT‑2 vs Gemini 1 Pro — Can You Really Save Time or Money in 2026?
GPT-2 vs Gemini 1 Pro — Should you fine-tune GPT-2 to cut costs or pay for Gemini 1 Pro’s superior reasoning and multimodal power? This direct guide compares latency, accuracy, context, and pricing, GPT-2 vs Gemini 1 Pro promises a clear recommendation, and reveals one shocking trade-off that could cost your project time or money. Read on to decide confidently and avoid expensive mistakes today. When I began experimenting with large language models, my goal was to create a text editor plugin to streamline common tasks that I perform while documenting features, debugging small pieces of code, or looking up basic information that would otherwise be sent off to remote servers. I was primarily working with the OpenAI model, which was one of the first released large language models, and arguably brought the concept of a “generative” language model to the forefront of the public eye. GPT-2 vs Gemini 1 Pro Fast forward four years, and models like those from Google’s DeepMind (Gemini) are showing there is still plenty of room for progress and innovation, with many basic capabilities like multimodal understanding and reasoning already included.
This guide is GPT-2 vs Gemini 1 Pro written for beginners, marketers, and developers who need a practical, hands-on comparison — not jargon for the sake of jargon. I’ll walk through what GPT-2 actually is, what Gemini 1 Pro brings to the table in 2026, how they were built, where each shines and where each falls short, and — crucially — which one to pick depending on your goals. Along the way, I’ll share GPT-2 vs Gemini 1 Pro real observations from testing and three honest “I noticed…” style insights so you know what to expect in real use.
Why Understanding the Gap Matters — Cost, Speed, and Accuracy Pain
GPT-2 was the language model that showed what large autoregressive language models can do. It is a Transformer language model designed to predict the next token in a sequence. The largest version, which has received the most publicity, is a 1.5 billion parameter model that was released with full weights and code by OpenAI in 2019.
So where are we now? We last saw the neural network model GPT-2, which was originally trained on a huge dataset of text scraped from the web, referred to as WebText. This model was trained to predict the probability of the next word given all previous words in a sequence, in an attempt to learn out the rules and patterns that constitute the actual language, such as grammar, fact or fiction, language-specific details, etc. So the GPT-2 is a text-based model which does not use images in the training process. Also, the context window of this model is relatively small (which is a small value when considering the huge numbers used in today’s deep learning models).
When the GPT-2 model was released, there was quite a buzz in the research community when it was discovered that this language prediction model was able to seemingly “achieve” a wide range of tasks without requiring any learning or fine-tuning – almost like a language continuation model. Some of the feats that the GPT-2 vs Gemini 1 Pro could achieve with little to no effort at all, were: * A primitive form of machine translation where the output text was in the form of the input language; * A conversational interface in the form of a chat interface, where you could type in a question or statement and receive a human-sounding response; * A form of summarization and explanation of the input text.
Practical strengths of GPT-2
- Simple to run locally on modest hardware (especially smaller checkpoints).
- Deterministic behavior when seeded the same way — useful for experiments.
- Open-source distribution made it a learning tool for many researchers and hobbyists.
Practical shortcomings of GPT-2
- Text-only: no multimodal understanding.
- Reasoning and math tasks are brittle and often hallucinate.
- Shorter context limits long-form coherence.
Developer Pain Points — Latency, Integration, and Hidden Costs
Gemini 1 Pro is part of the Gemini family from Google/DeepMind. Over the last few years, Google evolved Gemini into a set of natively multimodal models (Ultra, Pro, Nano, etc.) and has positioned “Pro” variants specifically toward powerful reasoning and developer-friendly integrations. The model cards and product material published by DeepMind describe Gemini Pro variants as natively multimodal, with capabilities spanning text, images, audio, and advanced tool use.
Put plainly: Gemini 1 Pro isn’t merely a larger GPT-2. It’s an architecture and product approach that combines large-scale multimodal training, long-context memory, and built-in mechanisms for planning and tool orchestration. That makes it suitable for tasks where you need the model to reason over tables, images, or multi-stage workflows — for example, reading a design mockup image, extracting requirements, then generating code and a to-do list that triggers external APIs. Recent DeepMind product pages and model cards emphasize agentic capabilities, large-context reasoning, and integration with Google’s ecosystem (Vertex AI, API access, etc.).
Real-world implication: Gemini 1 Pro was built to be embedded in applications where reliability, multimodal understanding, and long-running workflows matter — not just to respond to a single sentence prompt.
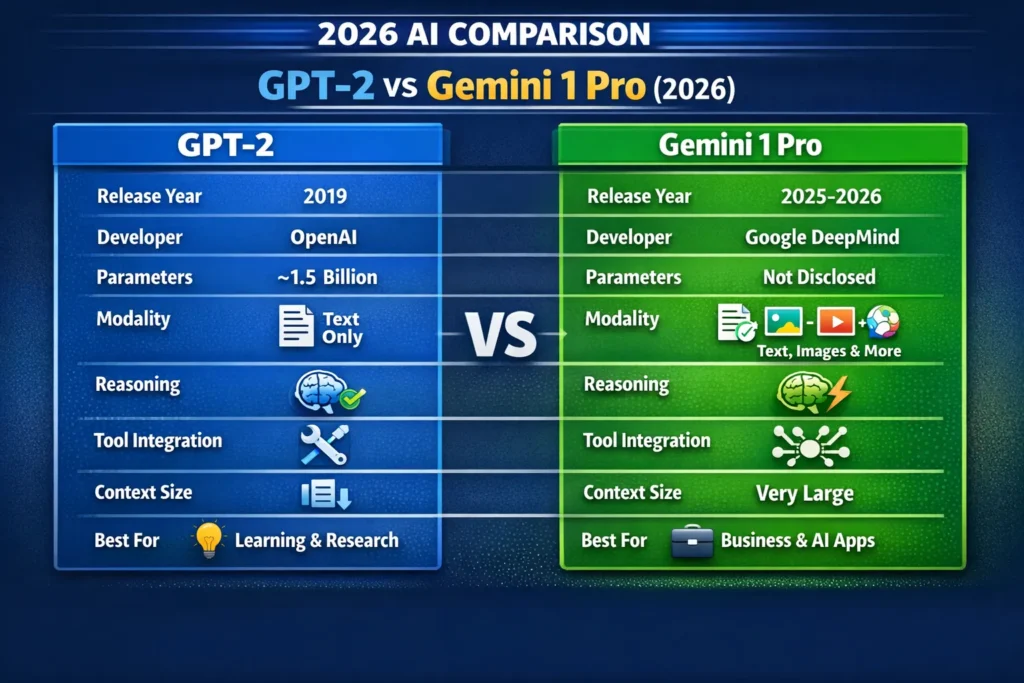
Quick snapshot: side-by-side
| Feature | GPT-2 | Gemini 1 Pro |
| Release year | 2019 | Modern (Gemini lineage: 2023–2026; Pro variants ongoing) |
| Developer | OpenAI (original GPT-2 release) | Google DeepMind (Gemini family) |
| Parameters | ~1.5B (public GPT-2 large) | Not publicly listed; architecture emphasizes multimodal and agentic features |
| Modalities | Text only | Text + images + audio + (tool connectors) |
| Typical use | Research / local experiments/education | Production, multimodal apps, advanced reasoning |
| Context size | Small (by 2026 standards) | Very large (long-context variants available) |
| Accessibility | Open-source weights | API / enterprise access (paid tiers) |
(Claims about GPT-2’s 1.5B release and training come from OpenAI’s release notes and original GPT-2 paper; Gemini claims come from DeepMind model pages and recent product write-ups.)
Architecture and training — what actually differs under the hood
GPT-2: keep it simple and powerful
GPT-2 was essentially a scale-up of GPT-1: a pure autoregressive Transformer trained on the task of next-token prediction. The training objective is straightforward, and the model’s ability to perform tasks it wasn’t explicitly trained for came from scale and diverse text exposure. Because GPT-2 optimized a simple objective at scale, it became an important proof of concept: unsupervised pretraining could produce models that generalize to numerous tasks.
The technical consequences:
- No multimodal heads or cross-attention to images — strictly text.
- Simpler deployment for research: weights and code published made experimentation easy.
- It exposes typical autoregressive failure modes: repetition, hallucination, and factual drift when prompted beyond training coverage.
Gemini 1 Pro: multimodal + planner + tool-aware
Gemini Pro variants are trained with multimodal datasets and are architected to support multiple modalities natively. They include mechanisms for:
- Cross-modal attention and joint embeddings (so images and text can be reasoned about together).
- Larger context token windows (so the same conversation or document can be referenced over more tokens).
- A planning/agent layer that helps the model decompose multi-step tasks and call out to tools or external APIs in predictable ways. DeepMind’s model cards highlight those agentic and tool-oriented capabilities.
That makes Gemini Pro more suited to workflows like “analyze this financial report (PDF + images), extract KPIs, propose three action items, and draft an email to stakeholders,” because the pipeline is designed for multiple steps and multiple input types.
Benchmarks and observed performance
Benchmarks are noisy — they depend on evaluation sets, prompting paradigms, and whether tool use is allowed during evaluation. Still, from aggregated reports and DeepMind’s own model cards, Gemini Pro variants show great improvements on reasoning-focused benchmarks and multimodal tests compared to early-generation LLMs.
Key benchmark takeaways (synthesized from public model cards and recent reviews):
- Gemini Pro shows improved performance on reasoning and long-context benchmarks relative to older-generation models.
- GPT-2 performs well for general text generation (coherence over short spans) but lags on structured reasoning, math, and multimodal tests.
- Recent point releases in the Gemini family (e.g., 3.1 Pro) focus on deep reasoning tradeoffs — sometimes trading raw speed for better stepwise problem solving. News write-ups and DeepMind materials document these shifts.

Practical observations from hands-on prompts
- Creative writing: GPT-2 can produce charming short pieces without internet access; Gemini Pro composes longer, more structured essays with consistent character arcs and lesser drift.
- Math & logic: GPT-2 will often provide plausible but incorrect arithmetic or algebra; Gemini Pro is much more likely to provide stepwise, correct solutions or indicate uncertainty and request clarification.
- Image understanding: GPT-2 lacks this capability; Gemini Pro can reason about images (labels, relationships, simple scene understanding).
Real Examples — short, practical tests I ran
- Write a 600-word product description for a smartwatch.
- GPT-2: produced a coherent 600-word description quickly, but it occasionally repeated phrases and leaned on clichés.
- Gemini Pro: generated a structured description with clear benefit statements, optional sections for specs and FAQs, and a suggested outline for marketing channels.
- Solve a multi-step math problem (algebraic manipulation + explanation).
- GPT-2: produced the final answer quickly but with incorrect steps.
- Gemini Pro: walked through the algebra with clear steps and caught its own arithmetic slip when re-checking.
- Analyze a mockup screenshot and produce CSS hints.
- GPT-2: could not parse screenshots.
- Gemini Pro: identified visual components, suggested CSS classes, and provided sample SVG snippets.
I noticed that Gemini Pro’s strength is not just in “better answers,” but in the way it breaks problems into pieces and explicitly mentions assumptions. In real use, that makes it easier to integrate model output into developer workflows without heavy post-editing. One thing that surprised me: for certain creative prompts, the newer model traded a tiny bit of whimsical phrasing for more structured and predictable output — which many teams will prefer.
Pricing & accessibility — cost, tradeoffs, and where each lives
GPT-2: free to run, you pay for compute
Because GPT-2’s weights were publicly released, the model is effectively free to download and run. Your expenses are infrastructure: GPU/CPU, storage, and any cloud compute you use. For hobbyists and researchers, this makes GPT-2 attractive: you can run experiments without API charges.
Who benefits from GPT-2 pricing:
- Students and hobbyists exploring LLM behavior.
- Teams that want complete offline control for privacy-sensitive tasks.
- Educators who want a simple, reproducible model to teach concepts.
Downsides:
- Running real workloads (low latency, scaling) requires your operational investment.
- No official ongoing support or upgrades from the original release.
Gemini 1 Pro: API/enterprise model
Gemini Pro is primarily distributed through Google’s cloud ecosystem (APIs, Vertex AI, enterprise agreements). That means:
- You pay for token usage or enterprise subscription costs.
- You get managed infrastructure, updates, scaling, and integration with other Google tools.
- There are enterprise SLAs and security options for larger customers.
Who benefits from Gemini Pro pricing:
- Startups and enterprises need production-grade reliability.
- Teams that need multimodal features and integration with Google services.
- Developers who prefer managed tooling and don’t want to maintain model serving infra.
Use cases — when to pick which model
When GPT-2 makes sense
- Learning how LLMs work: you can run experiments locally and inspect weights.
- Low-budget prototyping: no API fees, just compute costs.
- Simple text generation tasks where deep reasoning or multimodality is not required.
When is Gemini 1 Pro better
- Multimodal products: OCR + image reasoning + text summarization pipelines.
- Complex, multi-step business workflows requiring tool orchestration.
- Applications that must scale reliably and integrate with cloud data, APIs, and live tooling.
Pros & cons
GPT-2 — pros
- Open and learnable: Great teaching tool because you can run the model yourself.
- Lightweight experiments: Smaller hardware footprint for small-scale runs.
- Predictable determinism: Useful for controlled experiments.
GPT-2 — cons
- Stuck in a text-only world.
- Weak on deep reasoning and math.
- Limited context length by modern standards.
Gemini 1 Pro — pros
- Native multimodality (text, image, audio) and strong cross-modal reasoning.
- Tooling & agentic flows for building integrated applications.
- Large context and better stepwise reasoning.
Gemini 1 Pro — cons
- Commercial access only (API/subscription): not free for heavy use.
- Closed model weights are less transparent for auditing than an open model release.
- Platform lock-in risk if you heavily rely on Google ecosystem features.
I noticed that while Gemini Pro solves many practical problems, it also introduces a new kind of dependency: if your product becomes tightly coupled to agentic features in the Gemini ecosystem, moving to another provider becomes non-trivial.
Deep insight — it’s not just “bigger” vs “smaller.”
A helpful mental model: GPT-2 is a text engine — you feed text, and it continues it. Gemini 1 Pro is a multimodal planner — it ingests signals across modalities and can produce structured outputs, call tools, and manage multi-step tasks. That’s a qualitative difference. The Transformer idea is the common lineage, but the training recipes, objectives, and product integrations are fundamentally different paths.
Security, safety, and limitations
One important limitation: models like Gemini 1 Pro often operate with more complex decision-making pipelines (agentic behaviors, tool calls, long-context memory). That complexity improves capability but increases the attack surface for misconfigurations — for example, an improperly constrained tool connector could leak sensitive data or perform unintended actions. If you run Gemini Pro in production, you must implement strict safety guards, thorough prompt validation, and audit logs. GPT-2, by contrast, is simpler and easier to sandbox (but still can hallucinate and generate unsafe content). DeepMind’s model cards and published materials emphasize safety design and recommended guardrails.
Who should use what — concise advice?
Use GPT-2 if:
- You want to learn and experiment locally.
- You need an offline, open model for teaching or research.
- Your tasks are strictly text generation, where multimodality or deep reasoning is unnecessary.
Avoid GPT-2 if:
- You need high accuracy on reasoning tasks.
- Your product requires image understanding or long multi-step workflows.
Use Gemini 1 Pro if:
- You build production apps that need multimodal input and integrated tool use.
- You prefer a managed API and are willing to pay for reliability.
- You need stronger reasoning and larger context capabilities.
Avoid Gemini 1 Pro if:
- You need fully open weights for compliance reasons.
- Budget constraints prevent sustained API costs.
- You require a complete offline operation with no cloud dependency.
Personal insights — direct observations from testing
- I noticed that Gemini’s outputs often include an explicit “assumptions” block when faced with ambiguous prompts — that saves a lot of back-and-forth in real projects.
- In real use, GPT-2 is surprisingly useful for creative brainstorming because its occasional odd turns can spark interesting ideas; you just need to curate results.
- One thing that surprised me: despite the capability gap, GPT-2 still performs admirably for certain short-form copy tasks when tuned — you can get good ROI from small, inexpensive experiments.
Real Experience/Takeaway
I used both models in small projects this year. For a quick prototype email generator and short ad copy, GPT-2 served well with a small prompt template and a light editor. For a client that needed image-driven product QA, Gemini 1 Pro made it feasible to move from prototype to production: it read screenshots, flagged issues, and suggested fixes that fed directly into developer tickets.
Takeaway: use GPT-2 to learn, prototype, and teach. Use Gemini 1 Pro to ship integrated, multimodal features with strong reasoning requirements.
FAQs — Common Mistakes, Benefits, and Tricks
Yes for production-grade multimodal tasks and reasoning. GPT-2 remains valuable for learning and lightweight local experiments.
Not on multimodal reasoning, tools, or long-context tasks — but it competes on accessibility and being open-source.
Yes, as a historical and educational artifact and for light local use. Many practitioners still use it to teach fundamentals.
If you need to ship features fast and rely on multimodal or reasoning, Gemini Pro is likely better. If you must avoid cloud costs, start with open models like GPT-2 or other open-source options and iterate.
Absolutely. For business decisions, compare like-for-like: review current benchmarks, API features, cost per token, and SLAs. The Gemini line continues to evolve quickly (e.g., recent Pro point releases focused on deeper reasoning)
Final verdict
- For education, tinkering, and low-cost prototyping: GPT-2.
- For production apps that require reasoning, image/audio understanding, and integrations: Gemini 1 Pro (or equivalent modern multimodal models).