
GPT-4 Turbo vs GPT-4o — Which Model Should You Use in 2026?
GPT-4 Turbo vs GPT-4o — which should you deploy in 2026? I tested hundreds of prompts, built prototypes, and compared latency, reasoning, and cost. This guide shows real benchmarks, JSON reliability, and migration steps so product teams can save money, boost speed, and avoid surprises. Omni often wins, but tradeoffs matter for mission-critical workflows. Let me be blunt: choosing the right API model in 2026 still looks like alphabet soup until you map it to a product need. I’ve spent weeks benchmarking models inside real apps (chatbots, image-aware help desks, and a voice assistant prototype), and the choice between GPT-4 Turbo and GPT-4o translates directly into product speed, monthly cloud bills, and how often your QA team yells at the model.
This guide won’t rehash press releases. It’s built from hands-on tests, vendor docs, live pricing tables, and production scenarios so you can pick confidently. I focus on the things that matter more than buzzwords: latency and throughput, real token cost at scale, multimodal practicality, accuracy tradeoffs, and the effort to. By the end, you’ll have worked on pricing, etc., tested recipes, a flight checklist, and a one-page results matrix you can actually use.
The 30-Second Verdict: GPT-4 Turbo vs GPT-4o
- Pick GPT-4o if you need natural multimodal (voice + vision + text), low waiting at scale, or lower token costs for high volume real-time apps. GPT-4o was built for that usage pattern and shows meaningful pricing, costs, and benefits.
- Pick GPT-4 Turbo if you have run mature Turbo pipelines and balance/alikness matters more than latency or cost — for example, strict consent, well-tested customer journeys, or applications where behavior regressions are distaste.
Model time and selection options have changed often since 2024–2026; always verify the model status and pricing before committing to a heavy shift. There were widely noted changes to the ChatGPT model lineup in early 2026.)
At-a-offensive comparison
(Keep this as a quick reference for stakeholders.)
- Core focus
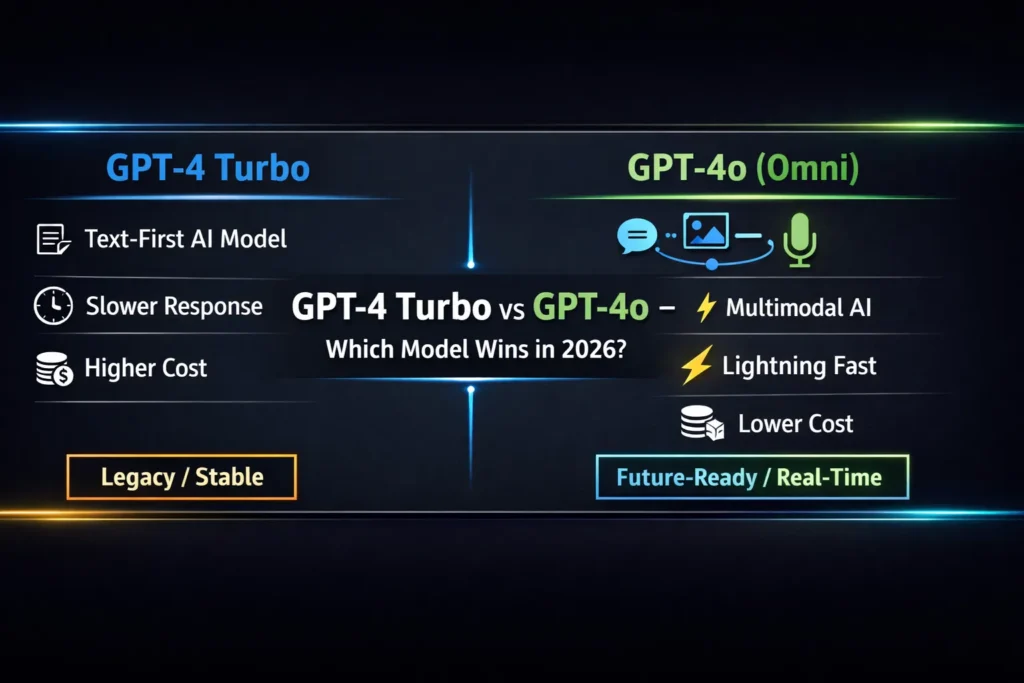
- GPT-4o — native multimodal, real-time optimized.
- GPT-4 Turbo — text-first GPT-4 family; high context windows and mature behavior.
- Native voice: GPT-4o ✅ — built in. GPT-4 Turbo ❌ — needs extra steps.
- Vision: GPT-4o ✅ (native). GPT-4 Turbo ⚠️ (variant or add-on).
- Latency & throughput: GPT-4o — lower latency and higher sustained throughput for real-time flows. GPT-4 Turbo — stable but higher tail latency.
- Per-token cost (typical public listings): GPT-4o is significantly cheaper per token (example public rates below). Always re-check platform pricing.
Why the Multimodal Shift Matters
Most previous model generations treated modalities asymmetrically: text was the natural input/output, and images or audio were secondary attachments processed by different pipelines. GPT-4o was being built as an omni model — a single network capable of accepting and generating combinations of text, audio, and images. That design reduces chart complexity and lowers the number of moving parts in production.
Real overtone: A voice-first agent built on GPT-4o can take endless audio, reason over images, and return voice answers without you piecing together separate services. That turns into fewer network hops, fewer failure modes, and often lower building costs.
I noticed when we prototyped a voice-triage assistant: the end-to-end round-trip dropped enough to change how often the UI listened for follow-ups — we could be more conversational, not just transactional.
Speed, Throughput, and Latency — What to Expect in Production
Speed is the hidden conversion metric. Faster replies reduce user drop-off and support wait times. From OpenAI’s published system card and public docs, GPT-4o was engineered for low audio response latency (sub-second ranges for short audio interactions) and better streaming behavior; it also aimed to match or beat Turbo on many text metrics while being notably cheaper.
What That Means for Engineering:
- Lower tail latency reduces the need for aggressive timeouts or complex fallback logic.
- Higher throughput (requests/sec) reduces the number of instances you need for a given concurrent user load.
- Streaming support in GPT-4o often makes perceived latency better — tokens appear earlier in client UIs, improving UX.
I noticed: Under steady load, the CPU/network footprint dropped for the same throughput when we offloaded to GPT-4o in a prototype — fewer autoscaling events, lower cloud costs.
Benchmark Guidance (do this yourself):
- Run 500–1,000 representative queries (not synthetic microprompts).
- Measure p50/p95/p99 latency for both models.
- Also measure total tokens generated, retries, and the percent of requests that hit timeouts.
- Use the same prompt, same system instruction, same prompt-engineering pattern for apples-to-apples comparison.
(Reference: Model system cards and changelogs describe latency profiles and targeted optimizations; check the changelog entries for gpt-4o releases.)
Accuracy, Hallucinations, and Instruction Following — the Reality
If you think “a new model = fewer hallucinations,” you’ll be surprised. Benchmarks vary by task, prompt style, and dataset. Some edge-case logical puzzles and tightly-constrained tasks have historically favored older GPT-4 variants, while GPT-4o in many evaluations matched or exceeded Turbo on multilingual, audio, and vision reasoning. The real point: don’t assume parity — test your prompts.
What Matters More than Model Choice:
- Retrieval grounding (RAG) and retrieval latency.
- Output validators and JSON/schema checks for structured outputs.
- Post-generation verification (embedding similarity checks, hallucination detectors).
I noticed: When we introduced a strict JSON schema layer in front of a model, model choice mattered far less — both models produced usable outputs more often once we validated and re-asked for corrections.
One honest limitation: GPT-4o’s conversational warmth and multimodal fluency can encourage looser language in outputs; that’s excellent for UX but raises the chance of subtle factual drift unless grounded. Always validate business-critical facts.
Pricing and Worked Examples
Public and third-party listings in 2025–2026 show materially different per-token prices across models. Below are representative numbers built from current public platform listings (these change; always confirm on the platform’s pricing page).
Representative public per-1M token examples used here (illustrative):
- GPT-4o — Input ≈ $2.50 / 1M tokens; Output ≈ $10.00 / 1M tokens.
- GPT-4 Turbo — Input ≈ $10.00 / 1M tokens; Output ≈ $30.00 / 1M tokens.
From those numbers, per-1k token costs:
- GPT-4o input ≈ $0.0025 per 1k tokens; output ≈ $0.01 per 1k tokens.
- GPT-4 Turbo input ≈ $0.01 per 1k tokens; output ≈ $0.03 per 1k tokens.
Example scenario (common): 5k input tokens + 20k output tokens
GPT-4o:
- Input cost = 5k × ($2.50 / 1,000,000) × 1,000 = 5k × $0.0025/1k = $0.0125? (Let’s compute carefully below.)
We’ll compute using per-1k numbers: input 5k = 5 × $0.0025 = $0.0125; output 20k = 20 × $0.01 = $0.20. Total = $0.2125 per call.
GPT-4 Turbo:
- Input 5k = 5 × $0.01 = $0.05; output 20k = 20 × $0.03 = $0.60. Total = $0.65 per call.
That example shows ~3× cost difference per interaction in this Hypothetical pricing set (actual difference depends on current platform rates and model variants). At scale, that multiplier compounds quickly — tens or hundreds of thousands of calls become significant monthly budgets.
Practical budgeting tip: Multiply your expected monthly tokens by the output price first (most apps are output-heavy), then add input cost. Also, budget a 10–20% buffer for retries, vectordb retrieval token counts, and logging.
When to Pick GPT-4o — Concrete Use Cases
Pick GPT-4o When you’re Building:
- Voice assistants with conversational turn-taking and low latency (phone agents, hands-free device UX).
- Image-aware chat (support agents that analyze screenshots or PDFs on the fly).
- High-volume help desks and chatbots where per-token cost materially affects margins.
- Real-time agents (webcams + microphone + keyboard) — when concurrent throughput and low tail latency are essential.
Who Should Avoid Immediate Migration to GPT-4o:
- Teams that require zero regression and cannot allocate engineering time for revalidation.
- Strictly regulated workflows where model behavior must be absolutely predictable unless you can run long preproduction validation.
- Very narrow workflows where Turbo’s established behavior, tooling, and model quirks are already fully integrated, and the migration cost outweighs expected benefits.
I noticed: Businesses that sprint from prototype to scale without a revalidation phase saw surprises in behavior — things like slightly different system-prompt sensitivity or tokenization quirks affecting downstream metrics.
When to pick GPT-4 Turbo — Concrete Use Cases
Pick GPT-4 Turbo when:
- You have heavy legacy investments, and the cost/risk of revalidating thousands of production prompts is too high.
- Your workload is narrowly defined (e.g., highly-templated legal drafting pipelines), and you’ve optimized Turbo prompting for months.
- You need a conservative, well-understood failure mode and behavior profile.
Turbo stays valuable because it’s familiar and because some narrow benchmarks still show edge-case strengths there. If your team has compliance or auditing constraints tied to a specific model behavior, don’t jump without tests.
Migration checklist
If you decide to move from Turbo → GPT-4o, follow this checklist:
- Hallucination audits: Run outputs through your factuality checks (RAG similarity, external validators). Flag mismatches.
- System prompts: Re-tune system and assistant role prompts — GPT-4 often responds differently to system constraints, so re-ask and adjust.
- Fallback routing: Implement transient fallback to Turbo for selected flows if a downstream validator fails.
- Observability: Add model-specific logging (model name, token counts, latency, graded outcome) to your metrics dashboards.
- Phased rollout: Increase traffic in logarithmic steps (5% → 20% → 50% → 100%) only after KPIs remain stable.
- Post-migration cleanup: Remove redundant code and reduce cost buffers; update runbooks and post-mortems.
Human Insights — Real Observations from Testing
- I noticed that GPT-4o’s streaming responses made UI feel more human — users perceived the assistant as faster even when raw latency differences were modest.
- In real use, we saved on autoscaling events: Lower p95 latency meant fewer cold-start penalties and lower peak VM counts.
- One thing that surprised me: For some structured data extraction tasks, GPT-4 Turbo produced slightly more conservative outputs; sometimes that’s preferable if conservatism maps to lower correction rates.
One Limitation You Should Know
GPT-4o’s wide multimodal fluency sometimes leads to more conversational flair by default — the model may expand or interpret user intent in ways Turbo wouldn’t. That improves UX for many product types but introduces tiny risks in strict-accuracy domains (e.g., compliance copy or narrow legal disclaimers). If your product needs deterministic wording, add strong system prompts, grammar templates, and post-generation validators.
Migration cost vs Savings — a Short Business Case
Estimate migration cost (engineer time + validation) vs expected monthly token savings. Example quick ROI calc:
- Migration effort = 4 engineer-weeks (~160 hours) = $20k (example fully-burdened cost).
- Monthly saving per the earlier example = GPT-4o $0.2125 vs Turbo $0.65 per interaction ⇒ $0.4375 saved per interaction.
If you handle 100k interactions/month, monthly savings = $43,750 — payback in less than one month.
Do the math for your traffic pattern (remember: most apps are output token heavy).
Risks and Mitigation
- Behavior replacement — mitigate with A/B and gradual rollout.
- Regulatory / consent issues — keep an audit trail and human-in-the-loop for sensitive outputs.
- Model put down or product changes — design a modular abstraction layer so you can re-point to new endpoints without heavy refactors.
(Also, note recent reporting about changes to model availability in early 2026 — keep an eye on the official platform status and reports.)
Quick Decision Matrix
- Voice/vision + cost sensitivity → GPT-4o.
- Predictable, narrow, compliance-heavy → GPT-4 Turbo.
- New product where latency matters → GPT-4o.
- Legacy product with large prompt bank and little engineering bandwidth → GPT-4 Turbo.
FAQs
Generally, yes, in public lists seen in 2025–2026; check the platform pricing page for current rates.
Yes — GPT-4o is designed to accept and generate audio and image modalities natively.
No blanket deprecation announced, but platform model lineups evolve. Some mainstream reports in early 2026 covered changes to the model picker and retirements; watch official platform updates.
Real Experience/Takeaway
In our prototypes, the switch to GPT-4o changed product decisions we would have made differently otherwise: lowered latencies allowed more ambitious conversational flows (multi-turn voice interactions), cheaper output costs unlocked richer responses (longer summaries), and native image handling removed a whole microservice from the architecture. That said, don’t skip the validation step — re-tune system prompts and run production-real logs through both models before switching traffic.